二分查找
二分查找是一种针对有序数据集合的查找算法。
假设有1000条订单数据,已经按照订单金额从小到大排序,每个订单金额都不同,并且最小单位是元。我们现在想知道是否存在金额等于19元的订单。如果存在,则返回订单数据,如果不存在则返回null。
最简单的办法当然是从第一个订单开始,一个一个遍历这1000个订单,直到找到金额等于19元的订单为止。但这样查找会比较慢,最坏情况下,可能要遍历完这1000条记录才能找到。那用二分查找能不能更快速地解决呢?
我们假设只有10个订单,订单金额分别是:8,11,19,23,27,33,45,55,67,98。
利用二分思想,每次都与区间的中间数据比对大小,缩小查找区间的范围。其中,low和high表示待查找区间的下标,mid表示待查找区间的中间元素下标。
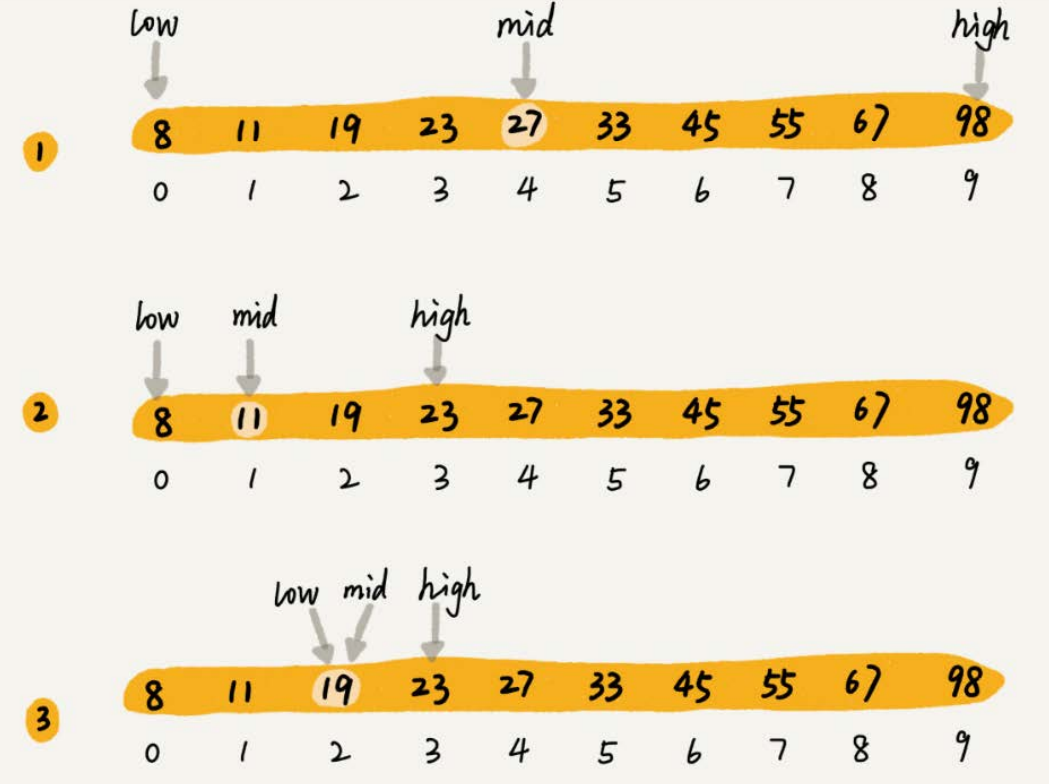
二分查找针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为0。
我们假设数据大小是n,每次查找后数据都会缩小为原来的一半,也就是会除以2。最坏情况下,直到查找区间被缩小为空,才停止。

这是一个等比数列,其中$n/2^k$=1时,k的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了k次区间缩小操作,时间复杂度就是O(k)。通过$n/2^k$=1,我们可以求得$k=\log_2 n$,所以时间复杂度就是O(logn)。
O(logn)是一种极其高效的时间复杂度,有的时候甚至比时间复杂度是常量级O(1)的算法还要高效。为什么这么说呢?
因为logn是一个非常“恐怖”的数量级,即便n非常非常大,对应的logn也很小。比如n等于2的32次方,这个数很大了吧?大约是42亿。也就是说,如果我们在42亿个数据中用二分查找一个数据,最多需要比较32次。
用大O标记法表示时间复杂度的时候,会省略掉常数、系数和低阶。对于常量级时间复杂度的算法来说,O(1)有可能表示的是一个非常大的常量值,比如O(1000)、O(10000)。所以,常量级时间复杂度的算法有时候可能还没有O(logn)的算法执行效率高。
二分查找递归和非递归实现
最简单的情况就是有序数组中不存在重复元素,我们在其中用二分查找值等于给定值的数据。
func BinarySearch(arr []int, target int) int {
low := 0
high := len(arr) - 1
for low <= high {
mid := (low + high) / 2
if arr[mid] == target {
return mid
} else if arr[mid] > target {
high = mid - 1
} else if arr[mid] < target {
low = mid + 1
}
}
return -1
}实际上,mid=(low+high)/2这种写法是有问题的。因为如果low和high比较大的话,两者之和就有可能会溢出。改进的方法是将mid的计算方式写成low+(high-low)/2。更进一步,如果要将性能优化到极致的话,我们可以将这里的除以2操作转化成位运算low+((high-low)»1)。因为相比除法运算来说,计算机处理位运算要快得多。
func BinarySearchRecursive(arr []int, target int) int {
if len(arr) == 0 {
return -1
}
return binarySearch(arr, 0, len(arr), target)
}
func binarySearch(arr []int, low, high, target int) int {
// 查找到最后一个元素,还是没有找到 target ,此时 low = high = mid ,
// 然后继续迭代,然后要么就是[mid+1,high],要么就是[low,high-1],
// 此时应该退出迭代了,因为数组中已经没有满足条件的值了。
// 故退出条件是 low > high
if low > high {
return -1
}
mid := low + ((high - low) >> 1)
if arr[mid] == target {
return mid
} else if arr[mid] < target {
return binarySearch(arr, mid+1, high, target)
} else {
return binarySearch(arr, low, mid-1, target)
}
}二分查找的局限性
二分查找依赖的是顺序表结构,简单点说就是数组。
那二分查找能否依赖其他数据结构呢?比如链表。答案是不可以的,主要原因是二分查找算法需要按照下标随机访问元素。数组按照下标随机访问数据的时间复杂度是O(1),而链表随机访问的时间复杂度是O(n)。所以,如果数据使用链表存储,二分查找的时间复杂就会变得很高。
二分查找只能用在数据是通过顺序表来存储的数据结构上。
其次,二分查找针对的是有序数据。数据必须是有序的。如果数据没有序,我们需要先排序。排序的时间复杂度最低是O(nlogn)。所以,如果我们针对的是一组静态的数据,没有频繁地插入、删除,我们可以进行一次排序,多次二分查找。这样排序的成本可被均摊,二分查找的边际成本就会比较低。
但是,如果我们的数据集合有频繁的插入和删除操作,要想用二分查找,要么每次插入、删除操作之后保证数据仍然有序,要么在每次二分查找之前都先进行排序。针对这种动态数据集合,无论哪种方法,维护有序的成本都是很高的。
再次,数据量太小不适合二分查找。
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为10的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多。只有数据量比较大的时候,二分查找的优势才会比较明显。
不过,这里有一个例外。如果数据之间的比较操作非常耗时,不管数据量大小,都推荐使用二分查找。 比如,数组中存储的都是长度超过300的字符串,如此长的两个字符串之间比对大小,就会非常耗时。我们需要尽可能地减少比较次数,而比较次数的减少会大大提高性能,这个时候二分查找就比顺序遍历更有优势。
最后,数据量太大也不适合二分查找。
二分查找的底层需要依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。比如,我们有1GB大小的数据,如果希望用数组来存储,那就需要1GB的连续内存空间。
练习
如何编程实现“求一个数的平方根”?要求精确到小数点后6位。
二分查找变形问题
默认有序数据集是从小到大排列为前提。
查找第一个值等于给定值的元素
比如下面这样一个有序数组,其中,a[5],a[6],a[7]的值都等于8,是重复的数据。我们希望查找第一个等于8的数据,也就是下标是5的元素。
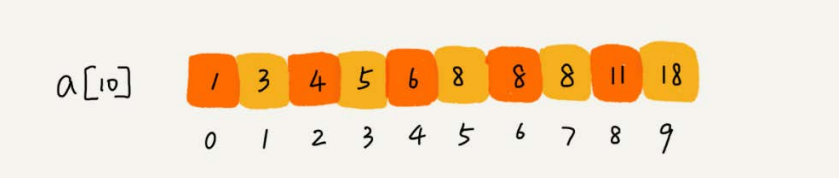
如果用之前那种简单的二分查找,首先拿8与区间的中间值a[4]比较,8比6大,于是在下标5到9之间继续查找。下标5和9的中间位置是下标7,a[7]正好等于8,所以代码就返回了。
尽管a[7]也等于8,但它并不是我们想要找的第一个等于8的元素,因为第一个值等于8的元素是数组下标为5的元素。
a[mid]跟要查找的value的大小关系有三种情况:大于、小于、等于。对于a[mid]>value的情况,我们需要更新high= mid-1;对于a[mid]<value的情况,我们需要更新low=mid+1。这两点都很好理解。那当a[mid]=value的时候应该如何处理呢?
如果我们查找的是任意一个值等于给定值的元素,当a[mid]等于要查找的值时,a[mid]就是我们要找的元素。但是,如果我们求解的是第一个值等于给定值的元素,当a[mid]等于要查找的值时,我们就需要确认一下这个a[mid]是不是第一个值等于给定值的元素。
func BinarySearchFirst(arr []int, target int) int {
low := 0
high := len(arr) - 1
for low <= high {
mid := low + ((high - low) >> 1)
if arr[mid] > target {
high = mid - 1
} else if arr[mid] < target {
low = mid + 1
} else {
// 如果mid等于0,那这个元素已经是数组的第一个元素,那它肯定是我们要找的;如果mid不等于0,但a[mid]的前一个元素a[mid-1]不等于value,那也说明a[mid]就是我们要找的第一个值等于给定值的元素。
if mid == 0 || arr[mid-1] != target {
return mid
} else {
// 如果经过检查之后发现a[mid]前面的一个元素a[mid-1]也等于value,那说明此时的a[mid]肯定不是我们要查找的第一个值等于给定值的元素。那我们就更新high=mid-1,因为要找的元素肯定出现在[low, mid-1]之间。
high = mid - 1
}
}
}
return -1
}查找最后一个值等于给定值的元素
func BinarySearchLast(arr []int, target int) int {
low := 0
high := len(arr) - 1
for low <= high {
mid := low + ((high - low) >> 1)
if arr[mid] > target {
high = mid - 1
} else if arr[mid] < target {
low = mid + 1
} else {
// 最后一个或者后一个
if mid == len(arr)-1 || arr[mid+1] != target {
return mid
} else {
// 肯定是在后半区
low = mid + 1
}
}
}
return -1
}查找第一个大于等于给定值的元素
func BinarySearchFirstMore(arr []int, target int) int {
low := 0
high := len(arr) - 1
for low <= high {
mid := low + ((high - low) >> 1)
if arr[mid] >= target {
if mid == 0 || arr[mid-1] < target {
return mid
} else {
high = mid - 1
}
} else {
low = mid + 1
}
}
return -1
}查找最后一个小于等于给定值的元素
func BinarySearchLastLess(arr []int, target int) int {
low := 0
high := len(arr) - 1
for low <= high {
mid := low + ((high - low) >> 1)
if arr[mid] <= target {
if mid == len(arr)-1 || arr[mid+1] > target {
return mid
} else {
low = mid + 1
}
} else {
high = mid - 1
}
}
return -1
}