排序
如何分析一个排序算法
排序算法的执行效率
- 最好情况、最坏情况、平均情况时间复杂度:我们在分析排序算法的时间复杂度时,要分别给出最好情况、最坏情况、平均情况下的时间复杂度。除此之外,你还要说出最好、最坏时间复杂度对应的要排序的原始数据是什么样的。对于要排序的数据,有的接近有序,有的完全无序。有序度不同的数据,对于排序的执行时间肯定是有影响的,我们要知道排序算法在不同数据下的性能表现。
- 时间复杂度的系数、常数 、低阶:在实际的软件开发中,我们排序的可能是10个、100个、1000个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
- 比较次数和交换(或移动)次数:基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。所以,如果我们在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
排序算法的内存消耗
算法的内存消耗可以通过空间复杂度来衡量,排序算法也不例外。不过,针对排序算法的空间复杂度,我们还引入了一个新的概念,原地排序(Sorted in place)。原地排序算法,就是特指空间复杂度是O(1)的排序算法。
排序算法的稳定性
针对排序算法,我们还有一个重要的度量指标,稳定性。这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
冒泡排序(Bubble Sort)
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复n次,就完成了n个数据的排序工作。
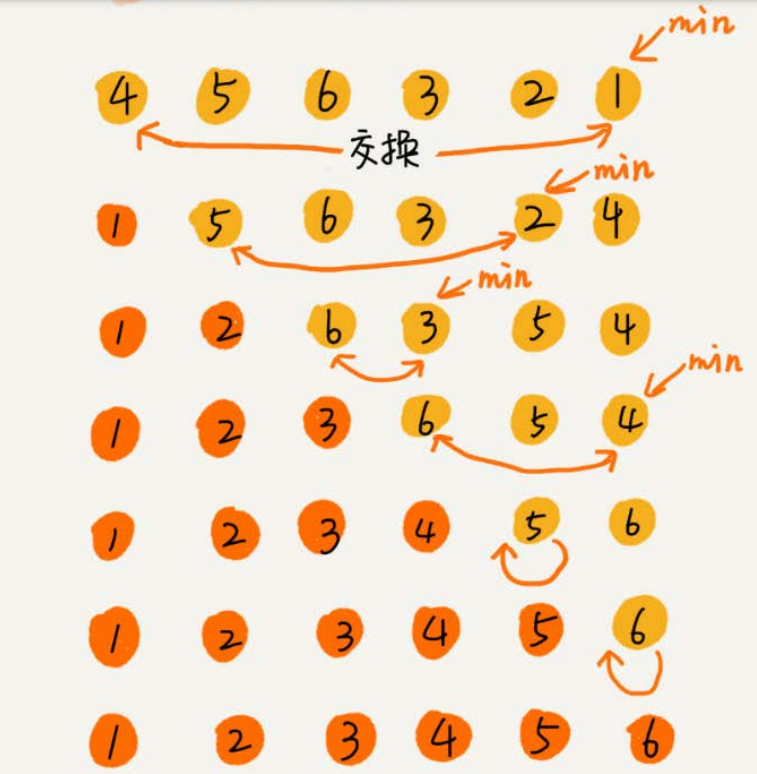
我们要对一组数据4,5,6,3,2,1,从小到到大进行排序。第一次冒泡操作的详细过程就是这样:
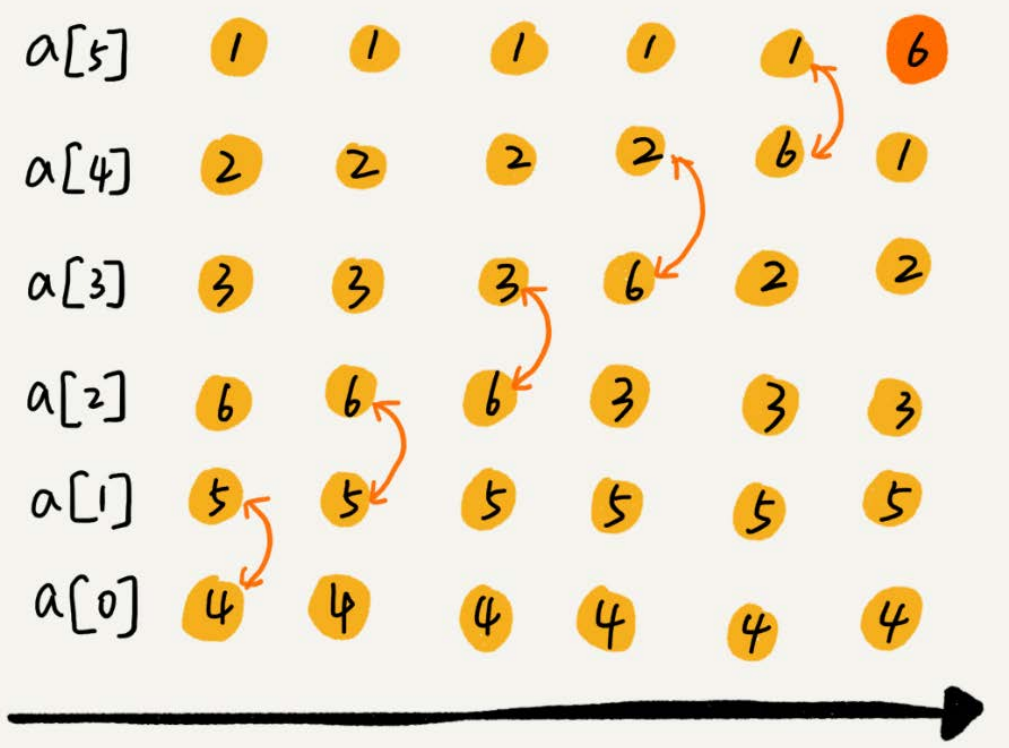
可以看出,经过一次冒泡操作之后,6这个元素已经存储在正确的位置上。要想完成所有数据的排序,我们只要进行6次这样的冒泡操作就行了。

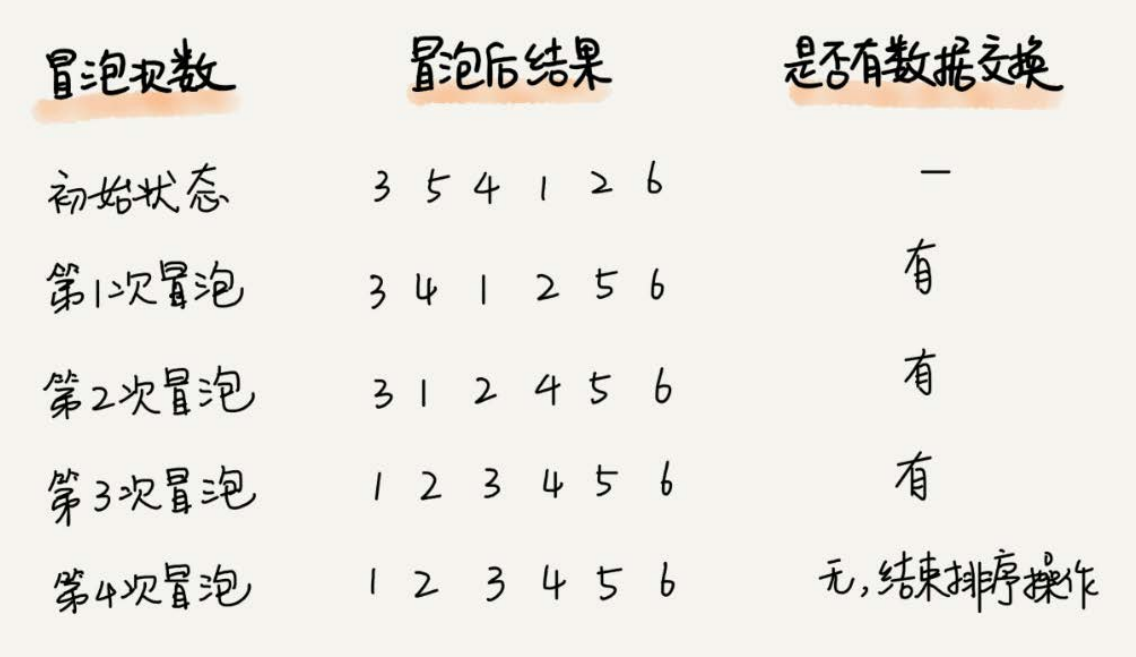
实际上,冒泡过程还可以优化。当某次冒泡操作已经没有数据交换时,说明已经达到完全有序,不用再继续执行后续的冒泡操作。我这里还有另外一个例子,这里面给6个元素排序,只需要4次冒泡操作就可以了。
func BubbleSort(arr []int) []int {
n := len(arr)
if n == 0 {
return []int{}
}
for i := 0; i < n; i++ {
flag := false // 提前退出冒泡排序的标志,默认没有发生交换
// 每一轮都少比较一个。因为每一轮都确定了一个最大位置
for j := 0; j < n-i-1; j++ {
if arr[j] > arr[j+1] {
tem := arr[j]
arr[j] = arr[j+1]
arr[j+1] = tem
// 发生交换
flag = true
}
}
if !flag {
break
}
}
return arr
}冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为O(1),是一个原地排序算法。
在冒泡排序中,只有交换才可以改变两个元素的前后顺序。为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,我们不做交换,相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
最好情况下,要排序的数据已经是有序的了,我们只需要进行一次冒泡操作,就可以结束了,所以最好情况时间复杂度是O(n)。而最坏的情况是,要排序的数据刚好是倒序排列的,我们需要进行n次冒泡操作,所以最坏情况时间复杂度为$O(n^2)$。
有序度是数组中具有有序关系的元素对的个数。有序元素对用数学表达式表示就是这样:
对于包含n个数据的数组,这n个数据就有n!种排列方式。不同的排列方式,冒泡排序执行的时间肯定是不同的。比如我们前面举的那两个例子,其中一个要进行6次冒泡,而另一个只需要4次。如果用概率论方法定量分析平均时间复杂度,涉及的数学推理和计算就会很复杂。我这里还有一种思路,通过“有序度”和“逆序度”这两个概念来进行分析。
有序元素对:a[i] <= a[j], 如果i < j。

同理,对于一个倒序排列的数组,比如6,5,4,3,2,1,有序度是0;对于一个完全有序的数组,比如1,2,3,4,5,6,有序度就是$\frac{n*(n-1)}{2}$,也就是15。我们把这种完全有序的数组的有序度叫作满有序度。
逆序度的定义正好跟有序度相反(默认从小到大为有序)。
逆序度=满有序度-有序度。我们排序的过程就是一种增加有序度,减少逆序度的过程,最后达到满有序度,就说明排序完成了。
要排序的数组的初始状态是4,5,6,3,2,1 ,其中,有序元素对有(4,5) (4,6)(5,6),所以有序度是3。n=6,所以排序完成之后终态的满有序度为n*(n-1)/2=15。
冒泡排序包含两个操作原子,比较和交换。每交换一次,有序度就加1。不管算法怎么改进,交换次数总是确定的,即为逆序度。此例中就是15–3=12,要进行12次交换操作。
对于包含n个数据的数组进行冒泡排序,平均交换次数是多少呢?最坏情况下,初始状态的有序度是0,所以要进行n*(n-1)/2次交换。最好情况下,初始状态的有序度是n*(n-1)/2,就不需要进行交换。我们可以取个中间值n*(n-1)/4,来表示初始有序度既不是很高也不是很低的平均情况。
换句话说,平均情况下,需要n*(n-1)/4次交换操作,比较操作肯定要比交换操作多,而复杂度的上限是$O(n^2)$,所以平均情况下的时间复杂度就是$O(n^2)$。
这个平均时间复杂度推导过程其实并不严格,但是很多时候很实用,毕竟概率论的定量分析太复杂,不太好用。
插入排序(Insertion Sort)
一个有序的数组,我们往里面添加一个新的数据后,如何继续保持数据有序呢?很简单,我们只要遍历数组,找到数据应该插入的位置将其插入即可。
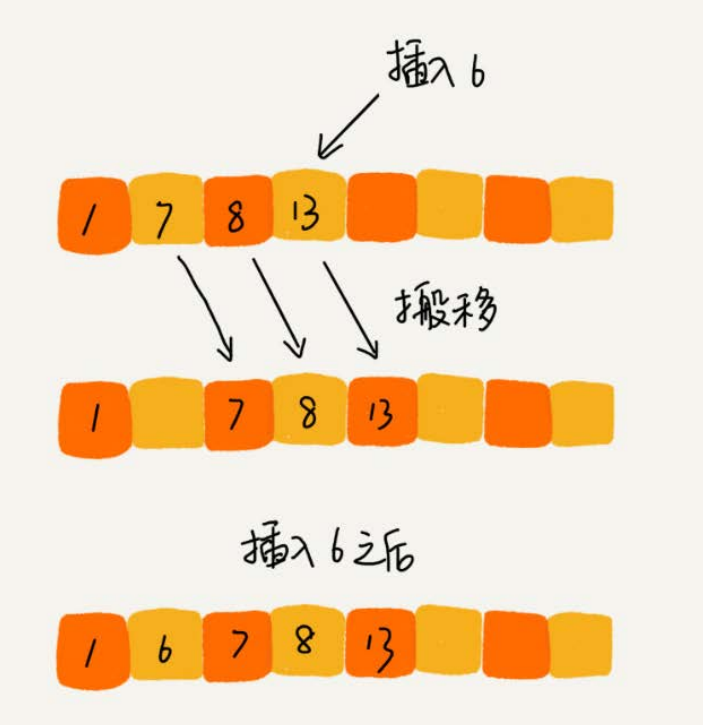
这是一个动态排序的过程,即动态地往有序集合中添加数据,我们可以通过这种方法保持集合中的数据一直有序。而对于一组静态数据,我们也可以借鉴上面讲的插入方法,来进行排序,于是就有了插入排序算法。
我们将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。
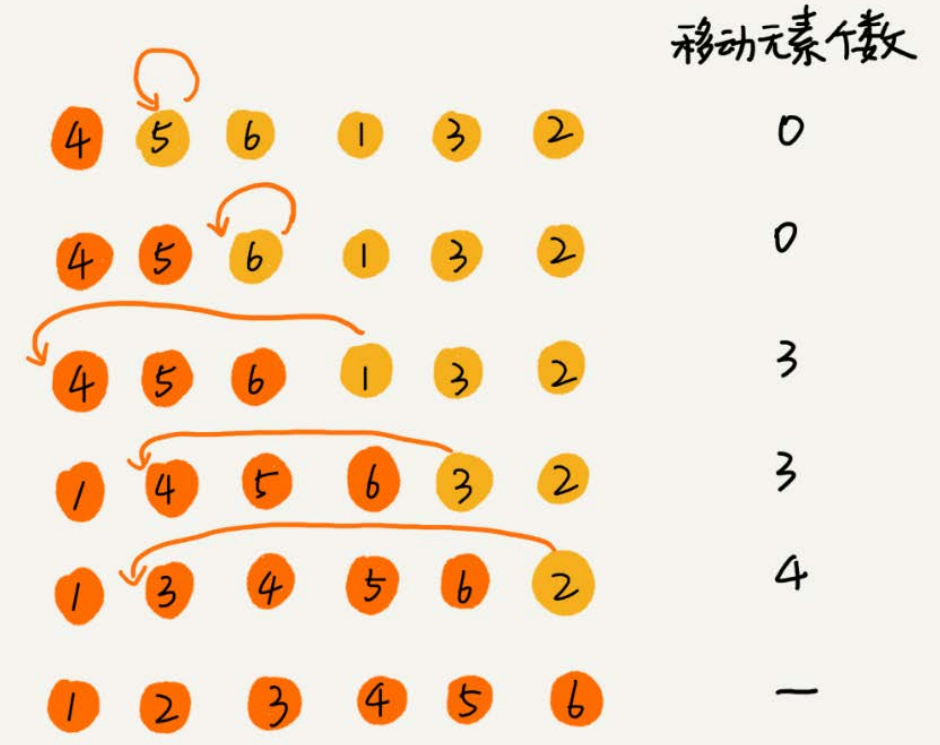
如图所示,要排序的数据是4,5,6,1,3,2,其中左侧为已排序区间,右侧是未排序区间。

插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据a插入到已排序区间时,需要拿a与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素插入。
对于不同的查找插入点方法(从头到尾、从尾到头),元素的比较次数是有区别的。但对于一个给定的初始序列,移动操作的次数总是固定的,就等于逆序度。
上例中,满有序度是n*(n-1)/2=15,初始序列的有序度是5,所以逆序度是10。插入排序中,数据移动的个数总和也等于10=3+3+4。
func InsertionSort2(arr []int) []int {
if len(arr) < 2 {
return arr
}
for i := 1; i < len(arr); i++ {
// 待插入的值
val := arr[i]
// 待比较的终点
j := i - 1
// 从右往左一遍遍历,一边挪位置
for ; j >= 0; j-- {
if arr[j] > val {
arr[j+1] = arr[j]
} else {
break
}
}
arr[j+1] = val
}
return arr
}插入排序显然是原地排序和稳定排序。
如果要排序的数据已经是有序的,我们并不需要搬移任何数据。如果我们从尾到头在有序数据组里面查找插入位置,每次只需要比较一个数据就能确定插入的位置。所以这种情况下,最好是时间复杂度为O(n)。注意,这里是从尾到头遍历已经有序的数据。如果数组是倒序的,每次插入都相当于在数组的第一个位置插入新的数据,所以需要移动大量的数据,所以最坏情况时间复杂度为$O(n^2)$。
在数组中插入一个值的平均复杂度是O(n)。所以,对于插入排序来说,每次插入操作都相当于在数组中插入一个数据,循环执行n次插入操作,所以平均时间复杂度为$O(n^2)$。
选择排序 (Selection Sort)
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
选择排序空间复杂度为O(1),是一种原地排序算法。选择排序的最好情况时间复杂度、最坏情况和平均情况时间复杂度都为$O(n^2)$。选择排序是一种不稳定的排序算法。从图中可以看出来,选择排序每次都要找剩余未排序元素中的最小值,并和前面的元素交换位置,这样破坏了稳定性。
func SelectSort(arr []int) []int {
if len(arr) < 2 {
return arr
}
// 第i轮交换,确定arr[i]最小
for i := 0; i < len(arr); i++ {
m := arr[i]
pos := i
for j := i; j < len(arr); j++ {
if arr[j] < m {
m = arr[j]
pos = j
}
}
arr[pos] = arr[i]
arr[i] = m
}
return arr
}思考
冒泡排序和插入排序的时间复杂度都是$O(n^2)$,都是原地排序算法,为什么插入排序要比冒泡排序更受欢迎呢?
冒泡排序不管怎么优化,元素交换的次数是一个固定值,是原始数据的逆序度。插入排序是同样的,不管怎么优化,元素移动的次数也等于原始数据的逆序度。
但是,从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要3个赋值操作,而插入排序只需要1个。我们来看这段操作:
if arr[j] > arr[j+1] {
tem := arr[j]
arr[j] = arr[j+1]
arr[j+1] = tem
// 发生交换
flag = true
}
if arr[j] > val {
arr[j+1] = arr[j]
} else {
break
}我们把执行一个赋值语句的时间粗略地计为单位时间(unit_time),然后分别用冒泡排序和插入排序对同一个逆序度是K的数组进行排序。用冒泡排序,需要K次交换操作,每次需要3个赋值语句,所以交换操作总耗时就是3*K单位时间。而插入排序中数据移动操作只需要K个单位时间。
归并排序 (Merge Sort)
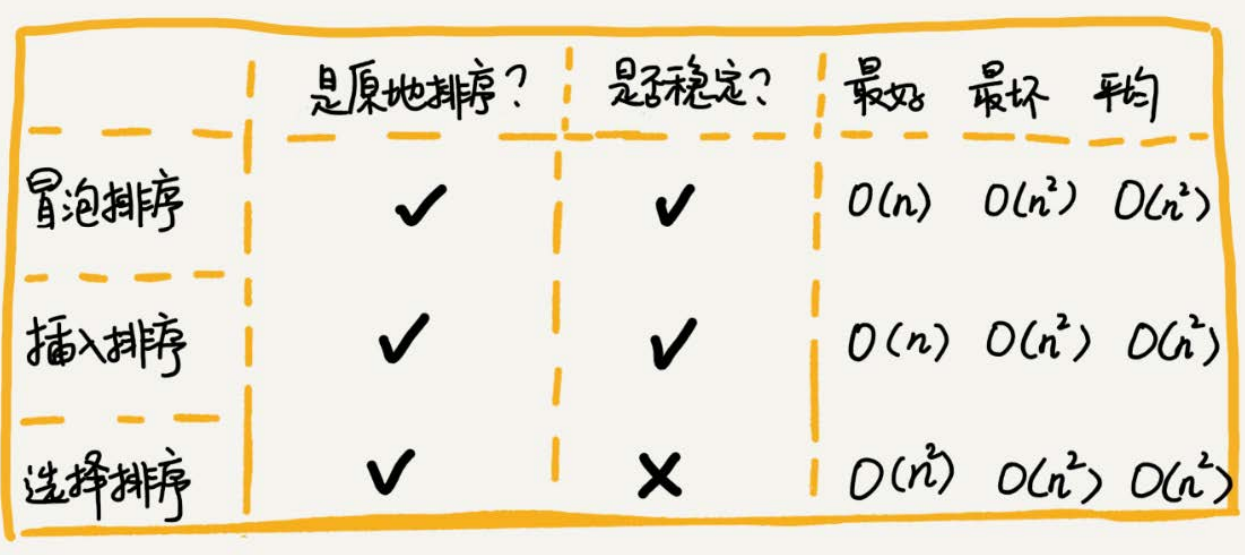
如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
分治思想跟递归思想很像。是的,分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p == r 不用再继续分解merge_sort(p…r)表示,给下标从p到r之间的数组排序。我们将这个排序问题转化为了两个子问题,merge_sort(p…q)和merge_sort(q+1…r),其中下标q等于p和r的中间位置,也就是(p+r)/2。当下标从p到q和从q+1到r这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从p到r之间的数据就也排好序了。
伪代码如下:
// 归并排序算法, A是数组,n表示数组大小
merge_sort(A, n) {
merge_sort_c(A, 0, n-1)
}
// 递归调用函数
merge_sort_c(A, p, r) {
// 递归终止条件
if p == r then return
// 取p到r之间的中间位置q
q = (p+r) / 2
// 分治递归
merge_sort_c(A, p, q)
merge_sort_c(A, q+1, r)
// 将A[p...q]和A[q+1...r]合并为A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}merge(A[p…r], A[p…q], A[q+1…r]) 这个函数的作用就是,将已经有序的 A[p…q]和 A[q+1….r]合并成一个有序的数组,并且放入 A[p….r]。那这个过程具体该如何做呢?
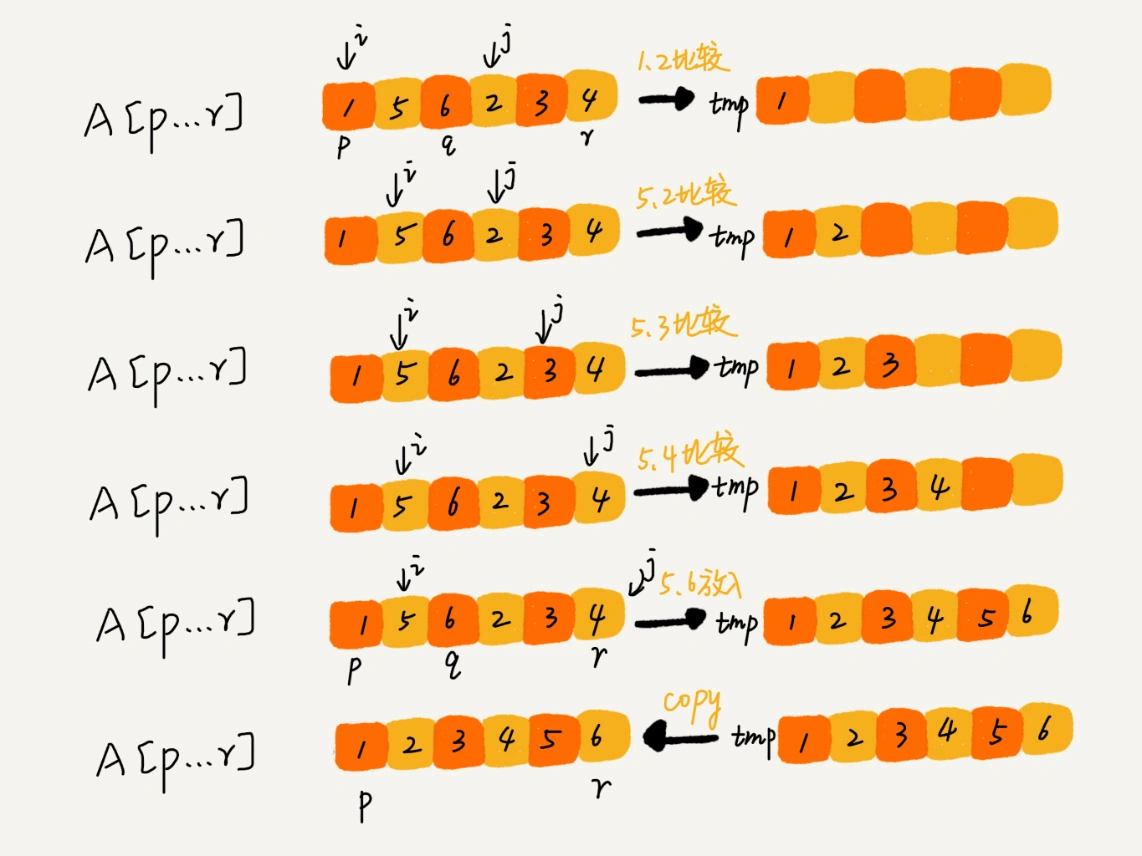
如上图所示,我们申请一个临时数组 tmp,大小与 A[p…r]相同。我们用两个游标 i 和 j,分别指向 A[p…q]和 A[q+1…r]的第一个元素。比较这两个元素 A[i]和 A[j],如果 A[i]<=A[j],我们就把 A[i]放入到临时数组 tmp,并且 i 后移一位,否则将 A[j]放入到数组 tmp,j 后移一位。
继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。最后再把临时数组 tmp 中的数据拷贝到原数组 A[p…r]中。
func MergeSort(arr []int) {
p := 0
q := len(arr) - 1
mergeSort(arr, p, q)
}
func mergeSort(arr []int, l, r int) {
if l == r {
return
}
// 默认向下取整
m := (l + r) / 2
mergeSort(arr, l, m)
mergeSort(arr, m+1, r)
// 直接对原始数组下标处理,也就是每一次递归,都完成了底层 l -> r 的排序,层层归上来,完成整个数组的排序
merge(arr, l, m, r)
}
func merge(arr []int, l, m, r int) {
temp := make([]int, r-l+1)
// 双指针
i := l
j := m + 1
// 临时数组下标
k := 0
for ; i <= m && j <= r; k++ {
if arr[i] <= arr[j] {
temp[k] = arr[i]
i++
} else {
temp[k] = arr[j]
j++
}
}
// 其中一组(不知道哪一组)遍历结束
// 左边没有遍历完
for ; i <= m; i++ {
temp[k] = arr[i]
k++
}
// 右边没有遍历完
for ; j <= r; j++ {
temp[k] = arr[j]
k++
}
copy(arr[l:r+1], temp)
}在合并的过程中,如果A[p…q]和A[q+1…r]之间有值相同的元素,先把A[p…q]中的元素放入tmp数组。这样就保证了值相同的元素,在合并前后的先后顺序不变。所以,归并排序是一个稳定的排序算法。
如果我们定义求解问题a的时间是T(a),求解问题b、c的时间分别是T(b)和 T( c),那我们就可以得到这样的递推关系式:
T(a) = T(b) + T(c) + K其中 K 等于将两个子问题 b、c 的结果合并成问题 a 的结果所消耗的时间。
不仅递归求解的问题可以写成递推公式,递归代码的时间复杂度也可以写成递推公式。
我们假设对 n 个元素进行归并排序需要的时间是 T(n),那分解成两个子数组排序的时间都是 T(n/2)。我们知道,merge() 函数合并两个有序子数组的时间复杂度是 O(n)。所以,套用前面的公式,归并排序的时间复杂度的计算公式就是:
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。
T(n) = 2*T(n/2) + n; n>1
T(n) = 2*T(n/2) + n
= 2*(2*T(n/4) + n/2) + n = 4*T(n/4) + 2*n
= 4*(2*T(n/8) + n/4) + 2*n = 8*T(n/8) + 3*n
= 8*(2*T(n/16) + n/8) + 3*n = 16*T(n/16) + 4*n
......
= 2^k * T(n/2^k) + k * n
......$T(n)=2^k * T(\frac{n}{2^k})+ k*n$。当 $T(\frac{n}{2^k})$ = T(1) 时,也就是 $\frac{n}{2^k}$ =1,我们可以得到 $k = \log_2 n$。我们将 k 值代入上面的公式,得到 $T(n)=Cn+n\log_2 n$ 。如果我们用大 O 标记法来表示的话,T(n) 就等于 O(nlogn)。所以归并排序的时间复杂度是 O(nlogn)。
归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
归并排序有一个致命的“弱点”,那就是归并排序不是原地排序算法。
这是因为归并排序的合并函数,在合并两个有序数组为一个有序数组时,需要借助额外的存储空间。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
快速排序 (Quick Sort)
快排的思想是这样的:如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
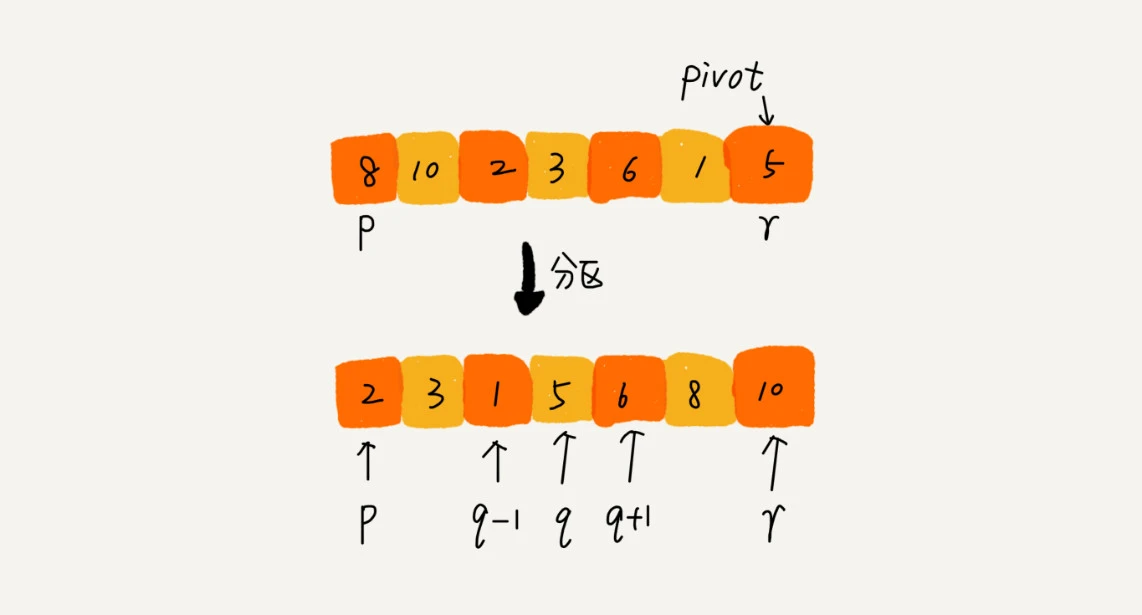
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
递推公式:
quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1… r)
终止条件:
p >= r伪代码如下:
// 快速排序,A是数组,n表示数组的大小
quick_sort(A, n) {
quick_sort_c(A, 0, n-1)
}
// 快速排序递归函数,p,r为下标
quick_sort_c(A, p, r) {
if p >= r then return
q = partition(A, p, r) // 获取分区点
quick_sort_c(A, p, q-1)
quick_sort_c(A, q+1, r)
}归并排序中有一个 merge() 合并函数,我们这里有一个 partition() 分区函数。partition() 分区函数实际上我们前面已经讲过了,就是随机选择一个元素作为 pivot(一般情况下,可以选择 p 到 r 区间的最后一个元素或者第一个元素),然后对 A[p…r]分区,函数返回 pivot 的下标。
如果我们不考虑空间消耗的话,partition() 分区函数可以写得非常简单。我们申请两个临时数组 X 和 Y,遍历 A[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到 A[p….r]。
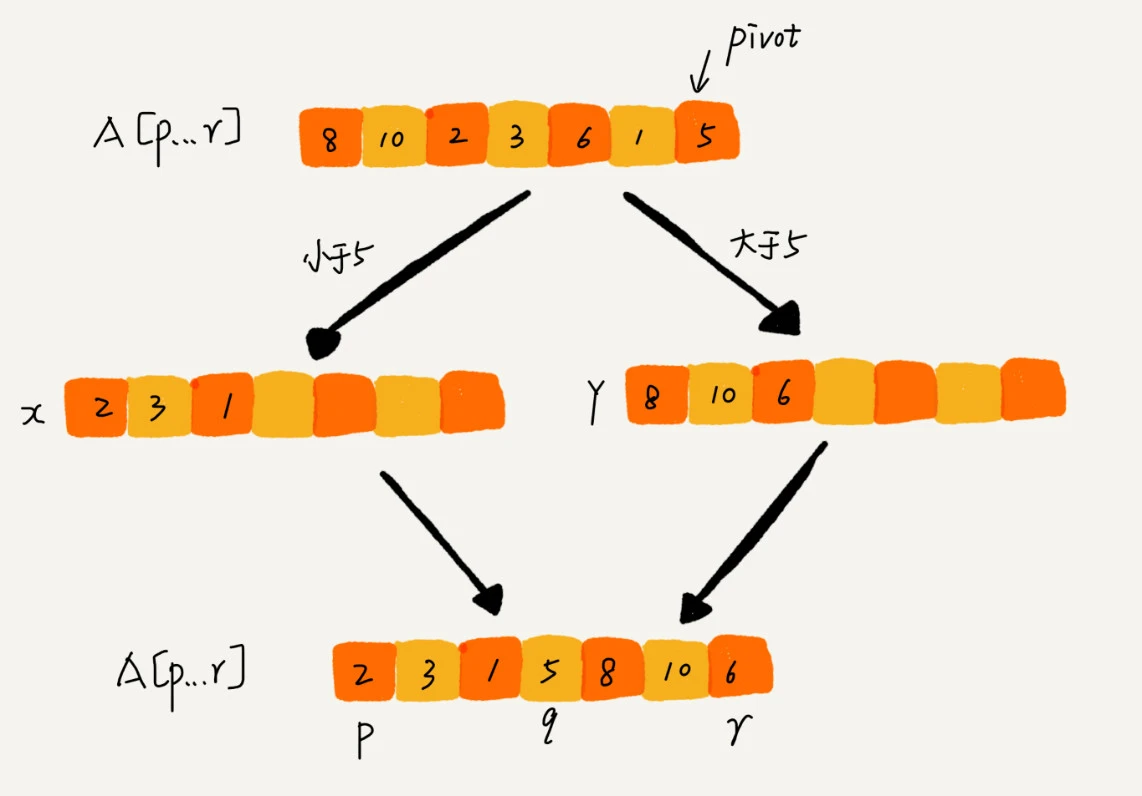
但是,如果按照这种思路实现的话,partition() 函数就需要很多额外的内存空间,所以快排就不是原地排序算法了。如果我们希望快排是原地排序算法,那它的空间复杂度得是 O(1),那 partition() 分区函数就不能占用太多额外的内存空间,我们就需要在 A[p…r]的原地完成分区操作。
伪代码如下:
partition(A, p, r) {
pivot := A[r]
i := p
for j := p to r-1 do {
if A[j] < pivot {
swap A[i] with A[j]
i := i+1
}
}
swap A[i] with A[r]
return i这里的处理有点类似选择排序。我们通过游标 i 把 A[p…r-1]分成两部分。A[p…i-1]的元素都是小于 pivot 的,我们暂且叫它“已处理区间”,A[i…r-1]是“未处理区间”。我们每次都从未处理的区间 A[i…r-1]中取一个元素 A[j],与 pivot 对比,如果小于 pivot,则将其加入到已处理区间的尾部,也就是 A[i]的位置。
在数组某个位置插入元素,需要搬移数据,非常耗时。有一种处理技巧,就是交换,在 O(1) 的时间复杂度内完成插入操作。这里我们也借助这个思想,只需要将 A[i]与 A[j]交换,就可以在 O(1) 时间复杂度内将 A[j]放到下标为 i 的位置。
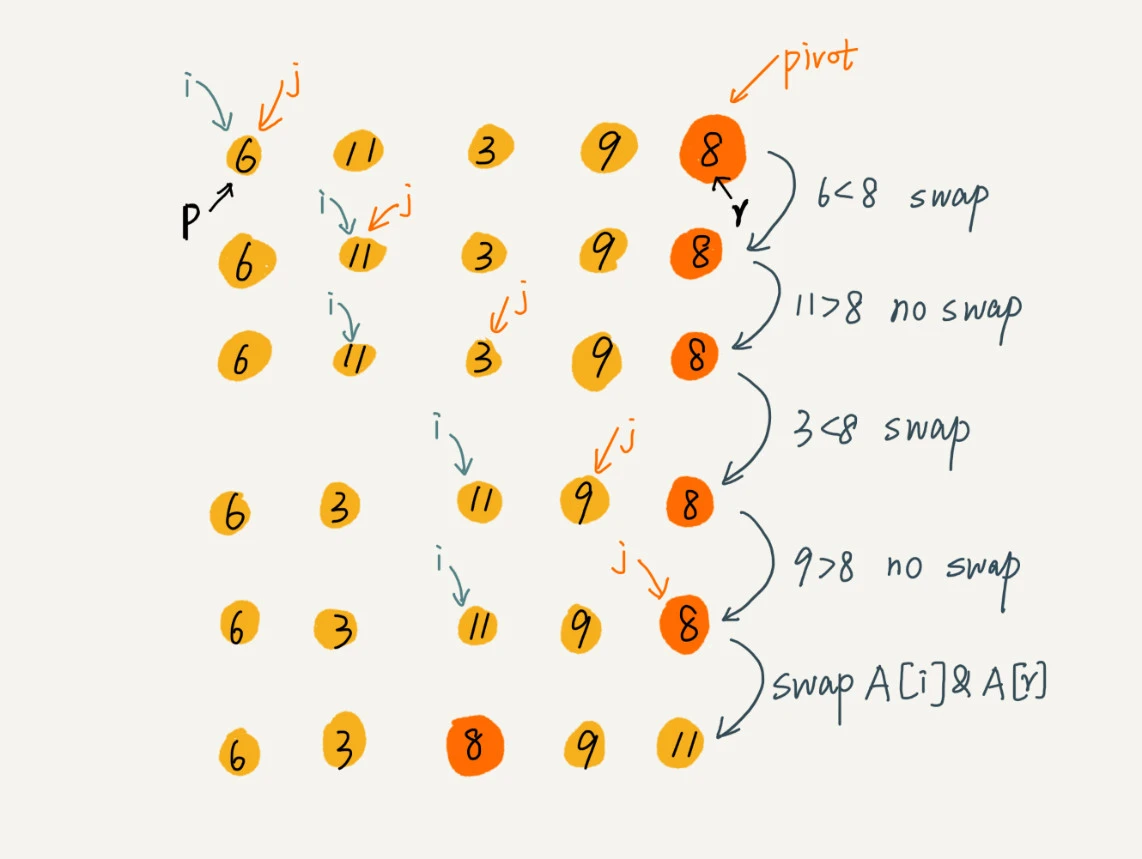
func QuickSort(arr []int) {
quickSort(arr, 0, len(arr)-1)
}
func quickSort(arr []int, l, r int) {
if l >= r {
return
}
q := partition(arr, l, r)
quickSort(arr, l, q-1)
quickSort(arr, q+1, r)
}
func partition(arr []int, l, r int) int {
pivot := arr[r]
i := l // 最终 pivot 所在的索引,,运行时指代的是未分区的第一索引位置
// 每次把 [j,r-1] 中默认都是没有比较的值,[l,i-1]都是处理比较好的数据(也就是小于pivot)
for j := l; j < r; j++ {
// 需要交换到 arr[j],这样 arr[j] 就小于 pivot,未处理区间缩小,i++
if arr[j] < pivot {
if i != j {
arr[i], arr[j] = arr[j], arr[i]
}
// 收缩未处理分区
i++
}
}
// 最后把 r(pivot)交换到 arr[i],返回 i
arr[i], arr[r] = arr[r], arr[i]
return i
}因为分区的过程涉及交换操作,如果数组中有两个相同的元素,比如序列 6,8,7,6,3,5,9,4,在经过第一次分区操作之后,两个 6 的相对先后顺序就会改变。所以,快速排序并不是一个稳定的排序算法。
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢?
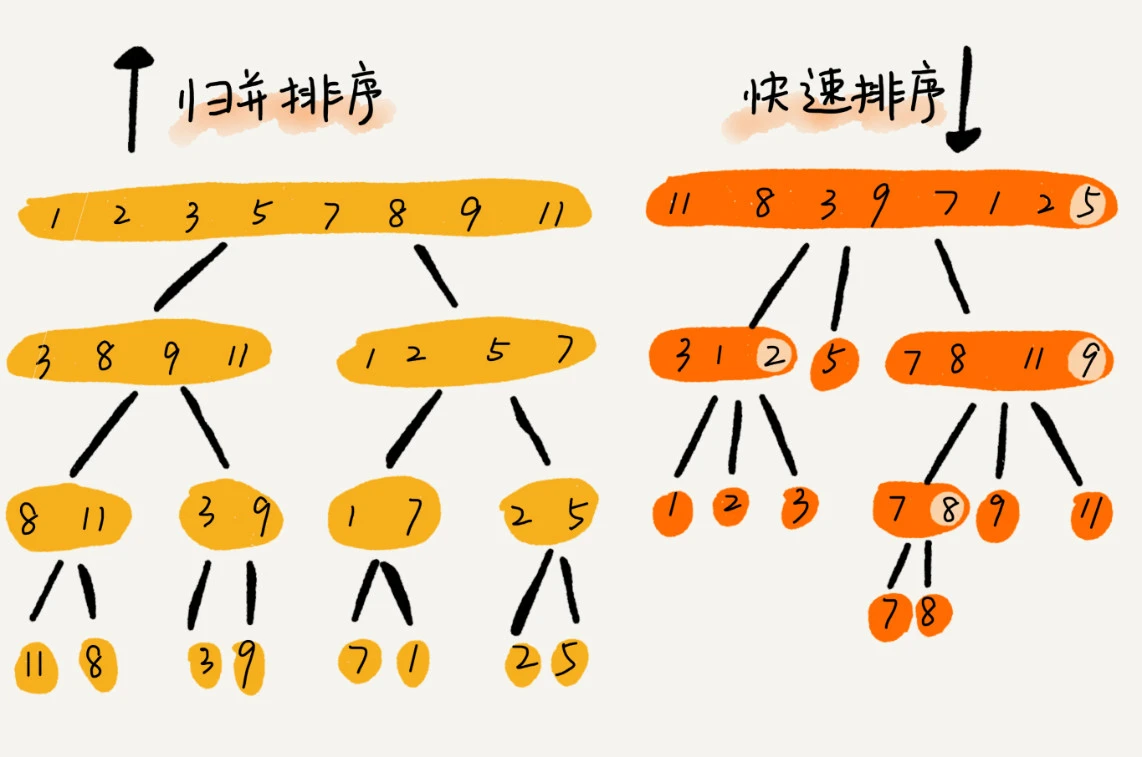
归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。
如果每次分区操作,都能正好把数组分成大小接近相等的两个小区间,那快排的时间复杂度递推求解公式跟归并是相同的。所以,快排的时间复杂度也是 O(nlogn)。
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。
T(n) = 2*T(n/2) + n; n>1但是,公式成立的前提是每次分区操作,我们选择的 pivot 都很合适,正好能将大区间对等地一分为二。但实际上这种情况是很难实现的。
如果数组中的数据原来已经是有序的了,比如 1,3,5,6,8。如果我们每次选择最后一个元素作为 pivot,那每次分区得到的两个区间都是不均等的。我们需要进行大约 n 次分区操作,才能完成快排的整个过程。每次分区我们平均要扫描大约 n/2 个元素,这种情况下,快排的时间复杂度就从 O(nlogn) 退化成了 $O(n^2)$。
T(n) 在大部分情况下的时间复杂度都可以做到 O(nlogn),只有在极端情况下,才会退化到 $O(n^2)$。
练习
O(n) 时间复杂度内求无序数组中的第 K 大元素。
比如,4, 2, 5, 12, 3 这样一组数据,第 3 大元素就是 4。
我们选择数组区间 A[0…n-1]的最后一个元素 A[n-1]作为 pivot,对数组 A[0…n-1]原地分区,这样数组就分成了三部分,A[0…p-1]、A[p]、A[p+1…n-1]。
如果 p+1=K,那 A[p]就是要求解的元素;如果 K>p+1, 说明第 K 大元素出现在 A[p+1…n-1]区间,我们再按照上面的思路递归地在 A[p+1…n-1]这个区间内查找。同理,如果 K < p+1, 那我们就在 A[0…p-1]区间查找。
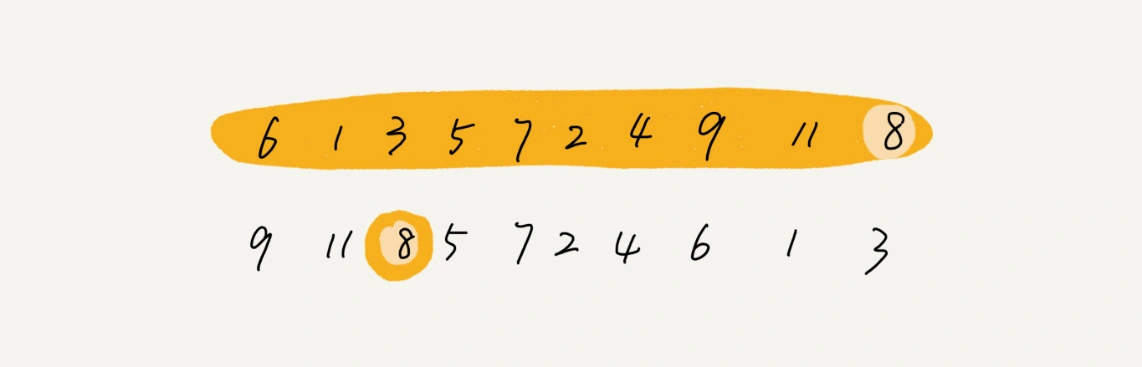
第一次分区查找,我们需要对大小为 n 的数组执行分区操作,需要遍历 n 个元素。第二次分区查找,我们只需要对大小为 n/2 的数组执行分区操作,需要遍历 n/2 个元素。依次类推,分区遍历元素的个数分别为、n/2、n/4、n/8、n/16.……直到区间缩小为 1。
如果我们把每次分区遍历的元素个数加起来,就是:n+n/2+n/4+n/8+…+1。这是一个等比数列求和,最后的和等于 2n-1。所以,上述解决思路的时间复杂度就为 O(n)。
你可能会说,我有个很笨的办法,每次取数组中的最小值,将其移动到数组的最前面,然后在剩下的数组中继续找最小值,以此类推,执行 K 次,找到的数据不就是第 K 大元素了吗?
不过,时间复杂度就并不是 O(n) 了,而是 O(K * n)。你可能会说,时间复杂度前面的系数不是可以忽略吗?O(K * n) 不就等于 O(n) 吗?当 K 是比较小的常量时,比如 1、2,那最好时间复杂度确实是 O(n);但当 K 等于 n/2 或者 n 时,这种最坏情况下的时间复杂度就是 $O(n^2)$ 了。
现在你有 10 个接口访问日志文件,每个日志文件大小约 300MB,每个文件里的日志都是按照时间戳从小到大排序的。你希望将这 10 个较小的日志文件,合并为 1 个日志文件,合并之后的日志仍然按照时间戳从小到大排列。如果处理上述排序任务的机器内存只有 1GB,你有什么好的解决思路,能“快速”地将这 10 个日志文件合并吗?
桶排序 (Bucket Sort)
核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

func BucketSort(arr []int) {
num := len(arr)
if num < 1 {
return
}
max := Max(arr)
// 二维切片
buckets := make([][]int, num) // 最大为 num,万一一个桶一个元素呢,每个元素就是桶
index := 0 // 桶序号
for i := 0; i < num; i++ {
index = arr[i] * (num - 1) / max // arr[i] / max = [0~1],然后乘以 num-1,按比例尽可能均匀分配到桶上,保证桶之间是有序的
buckets[index] = append(buckets[index], arr[i])
}
pos := 0 // 标记数组的位置
for i := 0; i < num; i++ {
bucketLen := len(buckets[i])
if bucketLen > 0 {
QuickSort(buckets[i]) // 依次快排
copy(arr[pos:], buckets[i]) // 排序写回原数组
pos += bucketLen
}
}
}
func Max(arr []int) int {
max := arr[0]
for i := 1; i < len(arr); i++ {
if arr[i] > max {
max = arr[i]
}
}
return max
}如果要排序的数据有n个,我们把它们均匀地划分到m个桶内,每个桶里就有k=n/m个元素。每个桶内部使用快速排序,时间复杂度为O(k * logk)。m个桶排序的时间复杂度就是O(m * k * logk),因为k=n/m,所以整个桶排序的时间复杂度就是O(n*log(n/m))。当桶的个数m接近数据个数n时,log(n/m)就是一个非常小的常量,这个时候桶排序的时间复杂度接近O(n)。
实际上,桶排序对要排序数据的要求是非常苛刻的。
首先,要排序的数据需要很容易就能划分成m个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。
其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为O(nlogn)的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
比如说我们有10GB的订单数据,我们希望按订单金额(假设金额都是正整数)进行排序,但是我们的内存有限,只有几百MB,没办法一次性把10GB的数据都加载到内存中。这个时候该怎么办呢?
我们可以先扫描一遍文件,看订单金额所处的数据范围。假设经过扫描之后我们得到,订单金额最小是1元,最大是10万元。我们将所有订单根据金额划分到100个桶里,第一个桶我们存储金额在1元到1000元之内的订单,第二桶存储金额在1001元到2000元之内的订单,以此类推。每一个桶对应一个文件,并且按照金额范围的大小顺序编号命名(00,01,02…99)。
理想的情况下,如果订单金额在1到10万之间均匀分布,那订单会被均匀划分到100个文件中,每个小文件中存储大约100MB的订单数据,我们就可以将这100个小文件依次放到内存中,用快排来排序。等所有文件都排好序之后,我们只需要按照文件编号,从小到大依次读取每个小文件中的订单数据,并将其写入到一个文件中,那这个文件中存储的就是按照金额从小到大排序的订单数据了。
不过,你可能也发现了,订单按照金额在1元到10万元之间并不一定是均匀分布的 ,所以10GB订单数据是无法均匀地被划分到100个文件中的。有可能某个金额区间的数据特别多,划分之后对应的文件就会很大,没法一次性读入内存。这又该怎么办呢?
针对这些划分之后还是比较大的文件,我们可以继续划分,比如,订单金额在1元到1000元之间的比较多,我们就将这个区间继续划分为10个小区间,1元到100元,101元到200元,201元到300元…901元到1000元。如果划分之后,101元到200元之间的订单还是太多,无法一次性读入内存,那就继续再划分,直到所有的文件都能读入内存为止。
显然不是原地排序,稳定性需要根据桶内排序决定,如果桶内排序用的是稳定性排序那自然是稳定排序,上面代码用的快排,则非稳定性排序。
计数排序 (Counting Sort)
计数排序其实是桶排序的一种特殊情况。当要排序的n个数据,所处的范围并不大的时候,比如最大值是k,我们就可以把数据划分成k个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
高考查分数的时候,系统会显示我们的成绩以及所在省的排名。如果你所在的省有50万考生,如何通过成绩快速排序得出名次呢?
考生的满分是900分,最小是0分,这个数据的范围很小,所以我们可以分成901个桶,对应分数从0分到900分。根据考生的成绩,我们将这50万考生划分到这901个桶里。桶内的数据都是分数相同的考生,所以并不需要再进行排序。我们只需要依次扫描每个桶,将桶内的考生依次输出到一个数组中,就实现了50万考生的排序。因为只涉及扫描遍历操作,所以时间复杂度是O(n)。
为什么这个排序算法叫“计数”排序呢?“计数”的含义来自哪里呢?
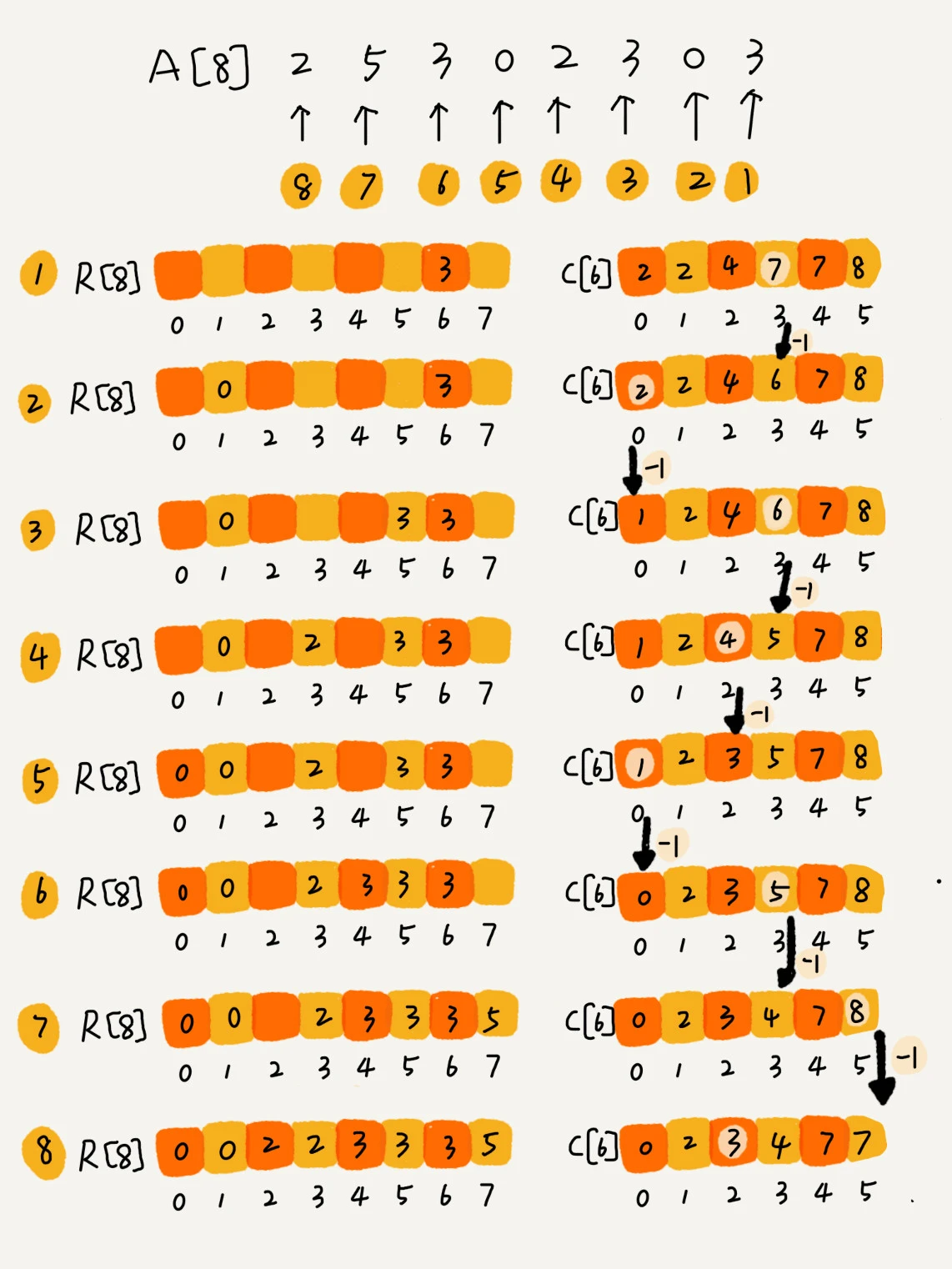
还拿考生那个例子来解释。为了方便说明,对数据规模做了简化。假设只有8个考生,分数在0到5分之间。这8个考生的成绩我们放在一个数组A[8]中,它们分别是:2,5,3,0,2,3,0,3。
考生的成绩从0到5分,我们使用大小为6的数组C[6]表示桶,其中下标对应分数。不过,C[6]内存储的并不是考生,而是对应的考生个数。像我刚刚举的那个例子,我们只需要遍历一遍考生分数,就可以得到C[6]的值。
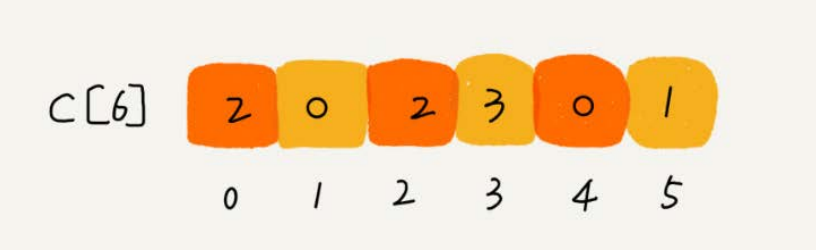
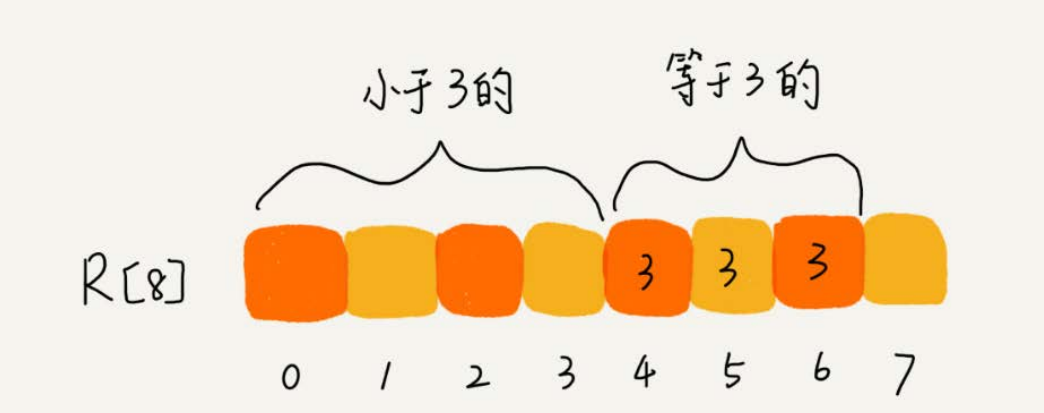
从图中可以看出,分数为3分的考生有3个,小于3分的考生有4个,所以,成绩为3分的考生在排序之后的有序数组R[8]中,会保存下标4,5,6的位置中。
那我们如何快速计算出,每个分数的考生在有序数组中对应的存储位置呢?
思路是这样的:我们对C[6]数组顺序求和,C[6]存储的数据就变成了下面这样子。C[k]里存储小于等于分数k的考生个数。
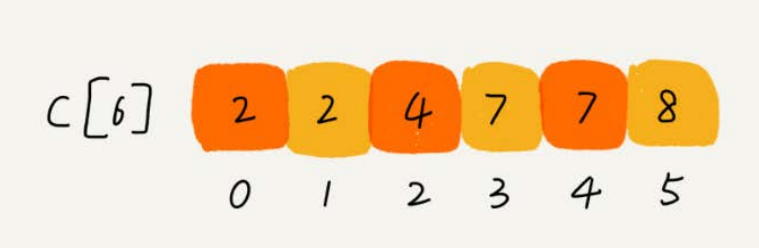
我们从后到前依次扫描数组A。比如,当扫描到3时,我们可以从数组C中取出下标为3的值7,也就是说,到目前为止,包括自己在内,分数小于等于3的考生有7个,也就是说3是数组R中的第7个元素(也就是数组R中下标为6的位置)。当3放入到数组R中后,小于等于3的元素就只剩下了6个了,所以相应的C[3]要减1,变成6。
func CountingSort(arr []int) {
if len(arr) <= 1 {
return
}
max := Max(arr)
c := make([]int, max+1) // 从 0 到 max+1,下标索引就代表这个 要排序的元素值
// 这个循环结束,c 每个下标对应的值 就代表 arr中元素值等于下标的元素有多少个
// 比如c[0] 代表在 待排序的数组(arr)中,0 有多少个,a[max] 代表 最大值有多少个
for i := 0; i < len(arr); i++ {
c[arr[i]]++
}
// 此时我们只知道 arr 中给一个元素,该元素有多少个,但是并不知道这个元素排序位置,也就是在这个元素之前有多少个
// 对c 进行顺序累加,这时候给定一个元素m,c[m]就代表 小于等于 c[m] 有多少个了。
// 但是仍然不知道该元素的排名,因为此时已经不知道该元素有多少个了,并且这个元素在一堆相同的元素中的排序
for i := 1; i < len(c); i++ {
c[i] += c[i-1]
}
// 倒序扫描 arr,每扫到一个元素m,该m肯定是所以一堆m 中最大的,也就是它的排序就是 c[m],然后 c[m]-1,下一次扫到 m 时候,这个 m 就是c[m]
r := make([]int, len(arr))
for i := len(arr) - 1; i >= 0; i-- {
index := c[arr[i]] - 1 // arr[i] 排序是 c[i],下标 -1
r[index] = arr[i] // 放入对应的序号
c[arr[i]]-- // 累加减一
}
copy(arr, r)
}
func Max(arr []int) int {
max := arr[0]
for i := 1; i < len(arr); i++ {
if arr[i] > max {
max = arr[i]
}
}
return max
}计数排序只能用在数据范围不大的场景中,如果数据范围k比要排序的数据n大很多,就不适合用计数排序了。而且,计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。
比如,还是拿考生这个例子。如果考生成绩精确到小数后一位,我们就需要将所有的分数都先乘以10,转化成整数,然后再放到9010个桶内。再比如,如果要排序的数据中有负数,数据的范围是[-1000, 1000],那我们就需要先对每个数据都加1000,转化成非负整数。
显然不是原地排序,但是是稳定排序(倒序扫描)。
基数排序 (Radix Sort)
假设我们有10万个手机号码,希望将这10万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
我们之前讲的快排,时间复杂度可以做到O(nlogn),还有更高效的排序算法吗?桶排序、计数排序能派上用场吗?手机号码有11位,范围太大,显然不适合用这两种排序算法。针对这个排序问题,有没有时间复杂度是O(n)的算法呢?现在我就来介绍一种新的排序算法,基数排序。
刚刚这个问题里有这样的规律:假设要比较两个手机号码a,b的大小,如果在前面几位中,a手机号码已经比b手机号码大了,那后面的几位就不用看了。
借助稳定排序算法,先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排序。经过11次排序之后,手机号码就都有序了。
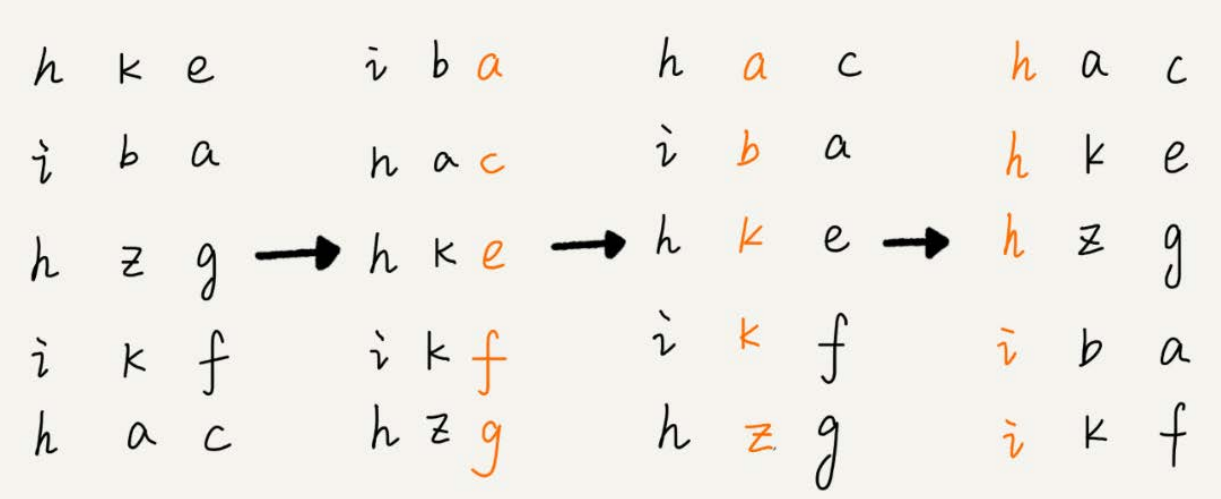
这里按照每位来排序的排序算法要是稳定的,否则这个实现思路就是不正确的。因为如果是非稳定排序算法,那最后一次排序只会考虑最高位的大小顺序,完全不管其他位的大小关系,那么低位的排序就完全没有意义了。
根据每一位来排序,我们可以用刚讲过的桶排序或者计数排序,它们的时间复杂度可以做到O(n)。如果要排序的数据有k位,那我们就需要k次桶排序或者计数排序,总的时间复杂度是O(k*n)。当k不大的时候,比如手机号码排序的例子,k最大就是11,所以基数排序的时间复杂度就近似于O(n)。
实际上,有时候要排序的数据并不都是等长的。对于这种不等长的数据,基数排序还适用吗?
实际上,我们可以把所有的单词补齐到相同长度,位数不够的可以在后面补“0”,因为根据ASCII值,所有字母都大于“0”,所以补“0”不会影响到原有的大小顺序。这样就可以继续用基数排序了。
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果a数据的高位比b数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到O(n)了。
func RadixSort(arr []int) {
// 最大值,判断总共多少位
max := Max(arr)
// 从最低位(个位)开始处理
exp := 1
// 向下取整,第一次循环对个位排序,第二次循环对十位排序 ...
for int(max/exp) > 0 {
arr = countingSortByExp(arr, exp)
exp *= 10
}
}
func countingSortByExp(arr []int, exp int) []int {
n := len(arr)
// 输出排序好的临时结果
output := make([]int, n)
// 0-9 共 10 位
count := make([]int, 10)
// 第一遍循环得到每个数字的 count,注意位数
for i := 0; i < n; i++ {
expNum := (arr[i] / exp) % 10 // 所在 exp 位的数字
count[expNum]++
}
// 顺序累加
for i := 1; i < 10; i++ {
count[i] += count[i-1]
}
// 倒序遍历 arr
for i := n - 1; i >= 0; i-- {
index := (arr[i] / exp) % 10
output[count[index]-1] = arr[i]
count[index]--
}
copy(arr, output)
return arr
}
func Max(arr []int) int {
max := arr[0]
for i := 1; i < len(arr); i++ {
if arr[i] > max {
max = arr[i]
}
}
return max
}练习
假设我们现在需要对D,a,F,B,c,A,z这个字符串进行排序,要求将其中所有小写字母都排在大写字母的前面,但小写字母内部和大写字母内部不要求有序。比如经过排序之后为a,c,z,D,F,B,A,这个如何来实现呢?如果字符串中存储的不仅有大小写字母,还有数字。要将小写字母的放到前面,大写字母放在最后,数字放在中间,不用排序算法,又该怎么解决呢?
排序优化
如果要实现一个通用的、高效率的排序函数,我们应该选择哪种排序算法?我们先回顾一下前面讲过的几种排序算法。
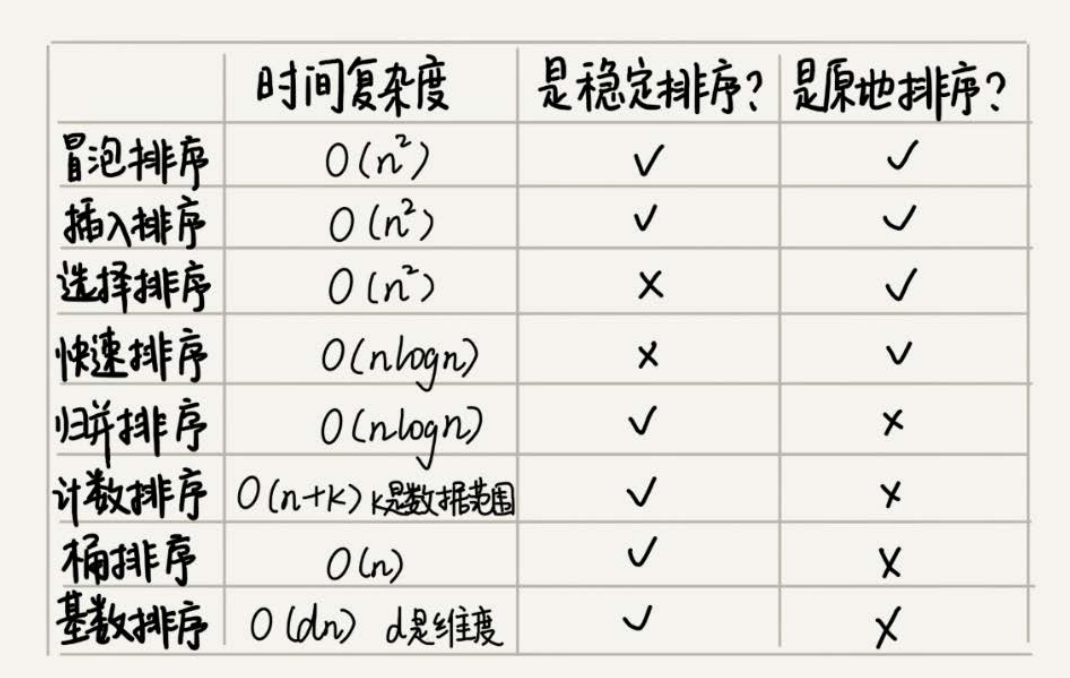
线性排序算法(O(n))的时间复杂度比较低,适用场景比较特殊。所以如果要写一个通用的排序函数,不能选择线性排序算法。
如果对小规模数据进行排序,可以选择时间复杂度是$O(n^2)$的算法;如果对大规模数据进行排序,时间复杂度是O(nlogn)的算法更加高效。所以,为了兼顾任意规模数据的排序,一般都会首选时间复杂度是O(nlogn)的排序算法来实现排序函数。比如Java语言采用堆排序实现排序函数,C语言使用快速排序实现排序函数。
快排在最坏情况下的时间复杂度是$O(n^2)$,而归并排序可以做到平均情况、最坏情况下的时间复杂度都是O(nlogn),从这点上看起来很诱人,那为什么很少使用它呢?归并排序并不是原地排序算法,空间复杂度是O(n)。所以,粗略点、夸张点讲,如果要排序100MB的数据,除了数据本身占用的内存之外,排序算法还要额外再占用100MB的内存空间,空间耗费就翻倍了。
快速排序比较适合来实现排序函数,但是,我们也知道,快速排序在最坏情况下的时间复杂度是$O(n^2)$,如何来解决这个“复杂度恶化”的问题呢?
如何优化快速排序
为什么最坏情况下快速排序的时间复杂度是$O(n^2)$呢?,如果数据原来就是有序的或者接近有序的,每次分区点都选择最后一个数据,那快速排序算法就会变得非常糟糕,时间复杂度就会退化为$O(n^2)$。实际上,这种O(n2)时间复杂度出现的主要原因还是因为我们分区点选的不够合理。
最理想的分区点是:被分区点分开的两个分区中,数据的数量差不多。
如果很粗暴地直接选择第一个或者最后一个数据作为分区点,不考虑数据的特点,肯定会出现之前讲的那样,在某些情况下,排序的最坏情况时间复杂度是$O(n^2)$。为了提高排序算法的性能,我们也要尽可能地让每次分区都比较平均。
- 三数取中法
我们从区间的首、尾、中间,分别取出一个数,然后对比大小,取这3个数的中间值作为分区点。这样每间隔某个固定的长度,取数据出来比较,将中间值作为分区点的分区算法,肯定要比单纯取某一个数据更好。但是,如果要排序的数组比较大,那“三数取中”可能就不够了,可能要“五数取中”或者“十数取中”。
- 随机法
随机法就是每次从要排序的区间中,随机选择一个元素作为分区点。这种方法并不能保证每次分区点都选的比较好,但是从概率的角度来看,也不大可能会出现每次分区点都选的很差的情况,所以平均情况下,这样选的分区点是比较好的。时间复杂度退化为最糟糕的O(n2)的情况,出现的可能性不大。
以 Glibc 中 qsort() 举例
- qsort()会优先使用归并排序来排序输入数据,因为归并排序的空间复杂度是O(n),所以对于小数据量的排序,比如1KB、2KB等,归并排序额外需要1KB、2KB的内存空间。
- 要排序的数据量比较大的时候,qsort()会改为用快速排序算法(三数取中法)来排序。
- 递归太深会导致堆栈溢出的问题,qsort()是通过自己实现一个堆上的栈,手动模拟递归来解决的。
- 在快速排序的过程中,当要排序的区间中,元素的个数小于等于4时,qsort()就退化为插入排序,不再继续用递归来做快速排序。在小规模数据面前,$O(n^2)$时间复杂度的算法并不一定比O(nlogn)的算法执行时间长。因为在大O复杂度表示法中,我们会省略低阶、系数和常数。