MPT
Trie(前缀树、字典树)
Trie ,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。 与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。 一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。 一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
前缀树的3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。 root节点不含字符这样做的目的是为了能够包括所有字符串。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
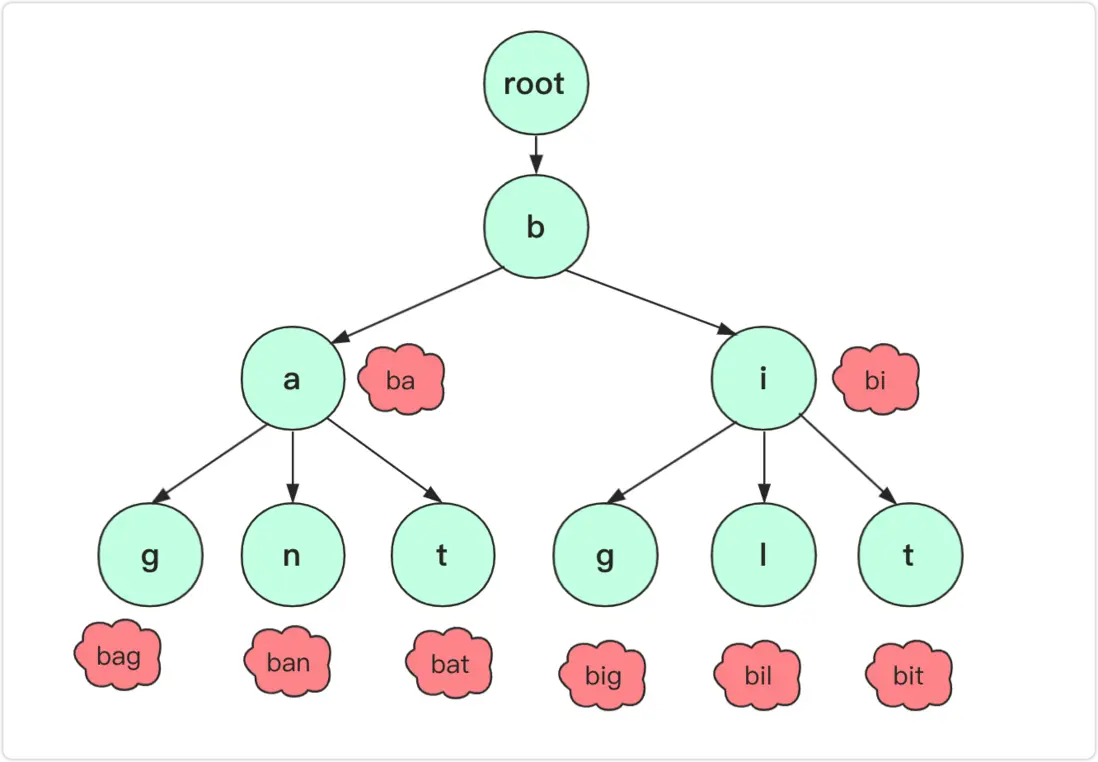
具体来说:例如我有 “a”、“apple”、“appeal”、“appear”、“bee”、“beef”、“cat” 这 7 个单词,那么就能够组织成如图所示字典树,如果我们要获取 “apple” 这个单词的信息,那么就按顺序访问对应的节点就行啦。
在简单的前缀树实现中,节点通常不直接存储值。节点的存在本身就是为了标识路径上的字符。然而,某些前缀树的实现会在终端节点(即代表键的完整路径的末尾节点)存储额外的信息,如是否是某个键的结尾、该键的出现次数、对应的值或其他与该键相关的数据。
Patricia Tree(压缩前缀树)
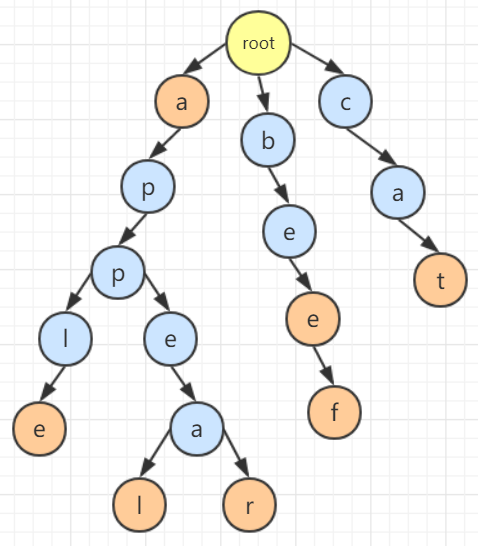
压缩前缀树,或称基数树,是一种更节省空间的 Trie(前缀树)。对于压缩前缀树的每个节点,如果该节点是确定的子树的话,就和父节点合并。
Merkle Patricia Tree
默克尔帕特里夏树(Merkle Patricia Tree)简称MPT树,是一个可以存储键值对 (key-value pair) 的高效数据结构,键、值分别可以是任意的序列化过的字符串。MPT树结合了字典树和默克尔树的优点,在压缩字典树中根节点是空的,而MPT树可以在根节点保存整棵树的哈希校验和,而校验和的生成则是采用了和默克尔树生成一致的方式。
节点
节点在逻辑上,由索引、路径和数据这三部分组成。
在实际中, 索引对应了数据库软件中一条记录的键;将路径和数据编码成一个单元,称为存储,对应了数据库软件中一条记录的“值”。
节点可以利用数据库软件例如MySQL、SQLite或轻量级数据库LevelDB来存储,它需要保证查询一个索引时候快速高效。
以太坊节点的路径是16格的Hex值,表示为0~f的16个元素,节点的第17个元素是节点存储。具体结构如下图所示, 数据库存储key和value为一组键值对。其中value包含了路径和数据 。

注意上图是数据库中的状态
请不要将索引(key)与路径(Path)混为一谈。
数据库“眼中”每一组数据 = 索引+存储, 而存储 = 路径+数据。
路径存在的意义是在组织数据的时候与其他数据关联的查找方式。
在以太坊中,数据库查找,我们简称为 dl操作(Database lookup) 。树路径查找,简称为 tl操作(Trie lookup)
初步构建一棵低效率的MPT树
假设我们拥有如下的键值对数据集。我们想办法用MPT树将其组织起来。
{
'cab8': 'dog',
'cabe': 'cat',
'39': 'chicken',
'395': 'duck',
'56f0': 'horse'
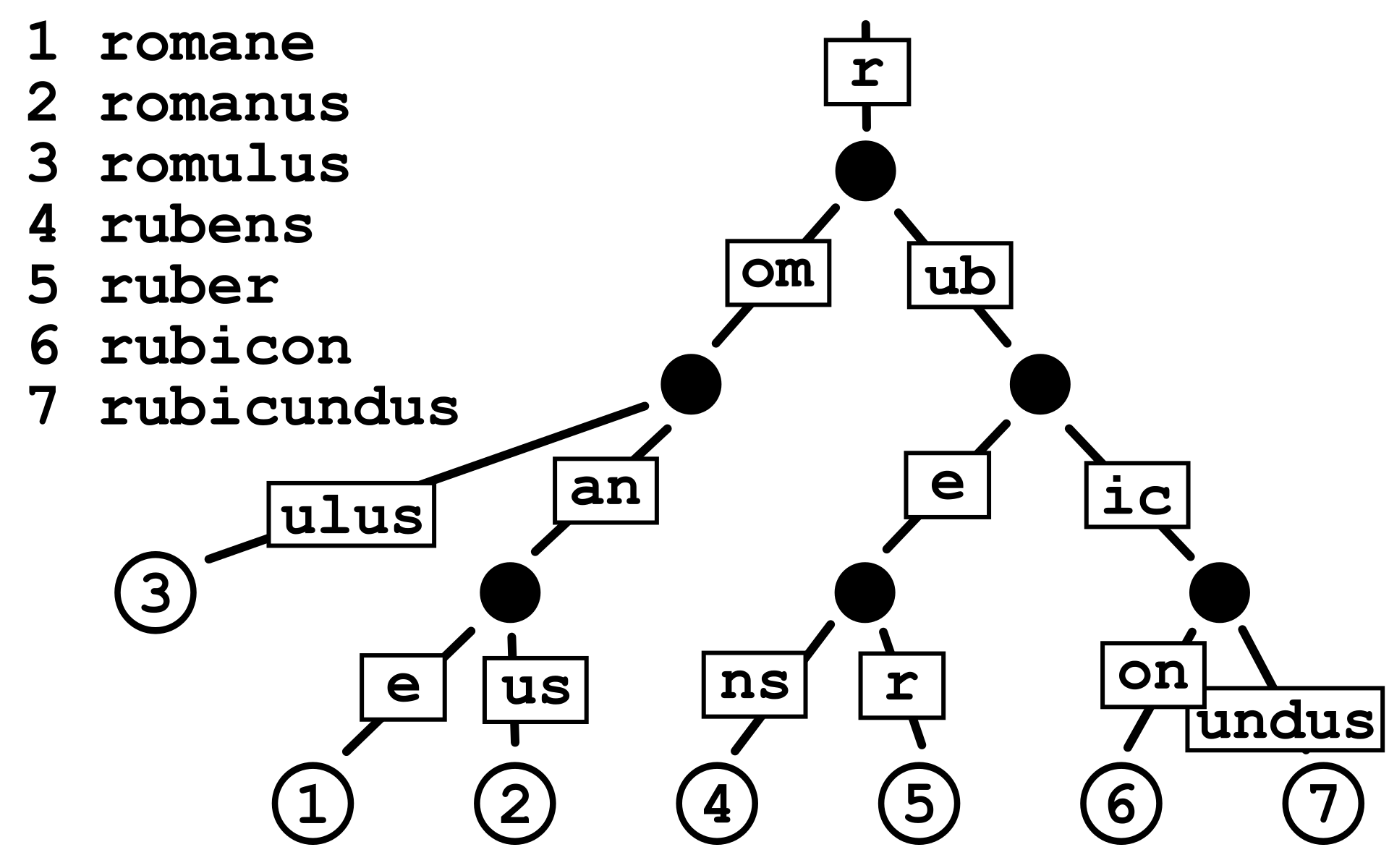
}我们仔细观察数据,首先想到的是Radix树的概念。cab8 和 cabe 共享了 cab 这个公共路径,39 和 395 共享了 39 这个路径。 56f0 因为和其他人没有重叠,所以自己单独一个路径。我们可以将这些路径按照字符拆开来,放入节点的路径中。
其次是诸如 “dog”, “cat” 之类的数据,它们千变万化,而且往往是一大块。不适合拆分,适合集中存放。我们将其放入节点的数据部分。
最后是校验和。因为我们希望这组数据作为一个整体,无论添加、删除、变更,都能立即体现出来。所以势必引入一个Merkle树的概念,对每层数据进行哈希,这是额外的功夫,这些哈希结果,放入索引部分。
具体拆分后是怎样存储的MPT树呢?

我们试着查找 路径 56f0 对应的数据:
- 拆分 56f0 为 5、6、f、0 四格。
- 我们首先确认这条数据位于一个数据集,这个数据集的索引是 rootHash 。
- 我们先做一次数据库查询找到该节点 (dl操作)。找到后,我们从这一行开始。
- 第一段路径为 5 ,我们取出路径顺序找到第5格,查询得知对该格对应的索引HashE (tl操作)。
- 根据 HashE 再次进行数据库查询 (dl操作),得到E节点,E节点不包含数据,所以它肯定是个叶子节点。
- 第二段路径为 6 ,我们路径查询 (tl操作) 得知对应索引 HashF。
- 以此类推,依序找到 HashG 、 HashH 。
- 取出 HashH 对应节点的数据 ,即为 “horse” ,查找完毕。
在该过程中我们交替使用了 数据库查找 和 路径查找 。 路径查找是Radix树的特色。把节点进行哈希进行索引,就是Merkle树的特色。两者完美结合。
但是这棵树还不够优化,存储空间有大量的空白值, HashE、HashF、HashG 的节点仅仅指向一个后继节点,在空间上效率不高,产生了退化 。
空间效率改进的MPT树
我们下面来改进一下这棵树,将部分节点改造合并、缩短路径,如图所示。

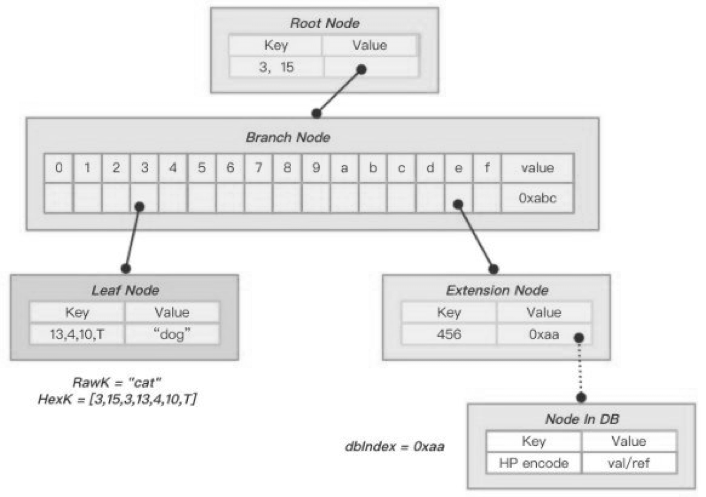
上述改造中我们引入了部分新的规则,节点不再是统一的格式,而是分化成了四种格式。
- 空节点(null):没有包含任何元素,用空字符串表示。
- 分支(branch):包含 17 个元素,前 16 个为 路径 ,末一个元素为 数据 。
- 叶子(leaf):仅包含 2 个元素,一个 路径 与一个 数据 。
- 扩展节点(extension):仅包含 2 个元素,一个 路径 和 索引 。
hashB 是一个扩展节点 ,它包含了部分路径 {ab} 与哈希存储 hashJ,这个扩展节点不是树的终点,因为它不包含可以返回的值,它明确指引查找者往下再去 hashJ 对应的节点查找值数据;
hashE 就是典型的叶子节点,它包含了部分路径 {6f0} 与最终值 “horse” ,它再也没有后继节点可供再查找下去;
hashC 是一个分支节点 ,它与叶子节点相似,包含了一个最终值 “chicken” ,但是也拥有一个对于 hashD 的索引,它不是树的终点,还可以往下继续查找下去。
根节点,分支节点,扩展节点,叶子节点的简化关系如图:
当我们在MPT树中查找路径 56f0 对应的 “horse” 值时,路径就大大缩短,按照如下步骤就可找到。
- 将查找总路径 56f0 分段为 5、6、f、0 。
- 从根节点 索引 rootHash 开始,我们先做一次数据库查询找到根节点(dl操作)。
- 第一个路径为 5 ,我们 路径 查询得知对应 索引 HashE (tl操作)。
- 根据 HashE 再次进行数据库查询,得到 E 节点。
- E 节点已经包含了剩下的部分路径 {6f0} ,命中,取出数据 “horse”。
以太坊上的MPT树
从宏观上来说,MPT树是一棵前缀树,用key查询value。通过key去查询value,就是用key去在MPT树上进行索引,在经过多个中间节点后,最终到达存储数据的叶子节点。
从细节上来说,MPT树,是一棵Merkle树,每个树上节点的索引,都是这个节点的hash值。在用key查找value的时候,是根据key在某节点内部,获取下一个需要跳转的节点的hash值,拿到下一个节点的hash值,才能从底层的数据库中取出下一个节点的数据,之后,再用key,去下一个节点中查询下下个节点的hash值,直至到达value所在的叶子节点。
当MPT树上某个叶子节点的数据更新后,此叶子节点的hash也会更新,随之而来的,是这个叶子节点回溯到根节点的所有中间节点的hash都会更新。最终,MPT根节点的hash也会更新。当要索引这个新的数据时,用MPT新的根节点hash,从底层数据库查出新的根节点,再往后一层层遍历,最终找到新的数据。而如果要查询历史数据,则可用老的树根hash,从底层数据库取出老的根节点,再往下遍历,就可查询到历史的数据。
通过以太坊黄皮书中很经典的一张图,来了解不同节点的具体结构和作用
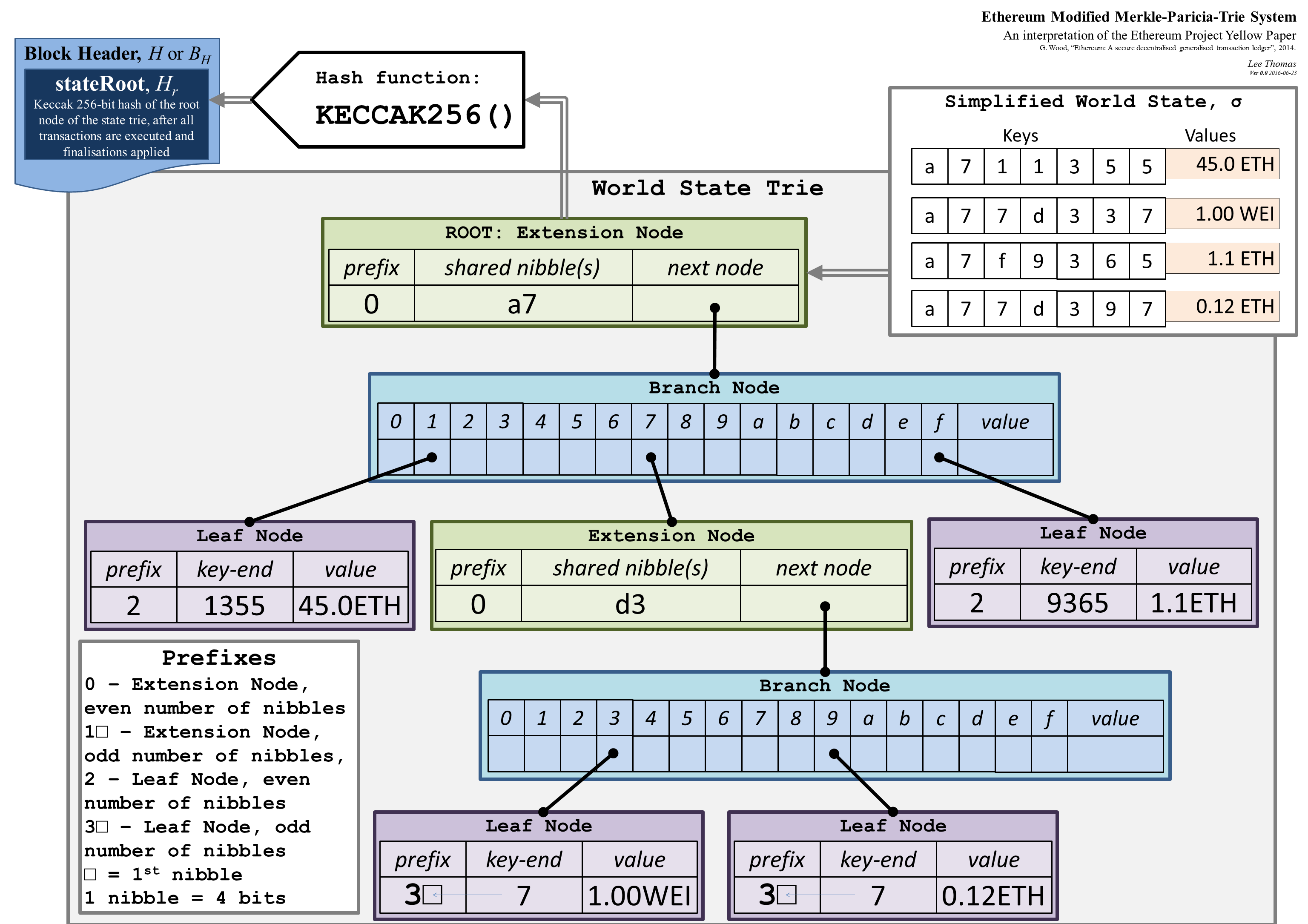
可以看到有四个状态要存储在世界状态的MPT树中,需要存入的值是键值对的形式。自顶向下,我们首先看到的keccak256生成的根哈希,参考默克尔树的Top Hash,其次看到的是绿色的扩展节点Extension Node,其中共同前缀shared nibble是a7,采用了压缩前缀树的方式进行了合并,接着看到蓝色的分支节点Branch Node,其中有表示十六进制的字符和一个value,最后的value是fullnode的数据部分,最后看到紫色的叶子节点leadfNode用来存储具体的数据,它同样对路径进行了压缩。
状态 State
在以太坊上,数据是以account为单位存储的,每个account内,保存着这个合约(用户)的代码、参数、nonce等数据。account的数据,通过account的地址(address)进行索引。以太坊上用MPT将这些address作为查询的key,实现了对account的查询。
随着account数据的改变,account的hash也进行改变。于此同时,MPT的根的hash也会改变。不同的时候,account的数据不同,对应的MPT的根就不同。此处,以太坊把这层含义进行了具体化,提出了“状态”的概念。把MPT根的hash,叫state root。不同的state root,对应着不同的“状态”,对应查询到不同的MPT根节点,再用account的address从不同的MPT根节点查询到此状态下的account数据。不同的state,拿到的MPT根节点不同,查询的account也许会有不同。
state root是区块中的一个字段,每个区块对应着不同的“状态”。区块中的交易会对account进行操作,进而改变account中的数据。不同的区块下,account的数据有所不同,即此区块的状态有所不同,具体的,是state root不同。从某个区块中取出这个区块的state root,查询到MPT的根节点,就能索引到这个区块当时account的数据历史。
以太坊的智能合约为例,智能合约部署成功后会得到一个地址,比如是0xa16de3199ca3ee1bc1e0926d53c12ffacdf3f2c4,除去开头的0x表示这是一个十六进制的字符串的标识,把其余字符按照压缩前缀树的规则存入MPT树,键(Key)就是合约的地址,键对应的值(Value)就是合约账户的信息,其中有合约代码和合约状态。合约中的状态变量又会做为一个键值对存入合约每个合约自己的MPT树中。相当于合约自己的MPT树又通过一个MPT树来进行组织。如果账户是外部账户,没有合约代码和合约状态,就直接存储了账户余额。而组织这一切的MPT树就叫世界状态树。世界状态树只需要存储每个合约状态树的根哈希,当合约状态变更,合约状态树的根哈希发生变化,传导到世界状态树,世界状态树的根哈希发生变化,从而让外部感知到世界状态发生了修改。
最终的数据还是以键值对的形式存储在LevelDB中的,MPT树相当于提供了一个缓存,帮助我们快速找到需要的数据。
MPT 树持久化
在Go实现的以太坊中,MPT树最终是存储在LevelDB数据库中的,LevelDB是Google开源的持久化KV单机数据库,具有很高的随机写,顺序读/写性能。以太坊通过对叶子节点按照一定的编码规则编码后存入LevelDB。
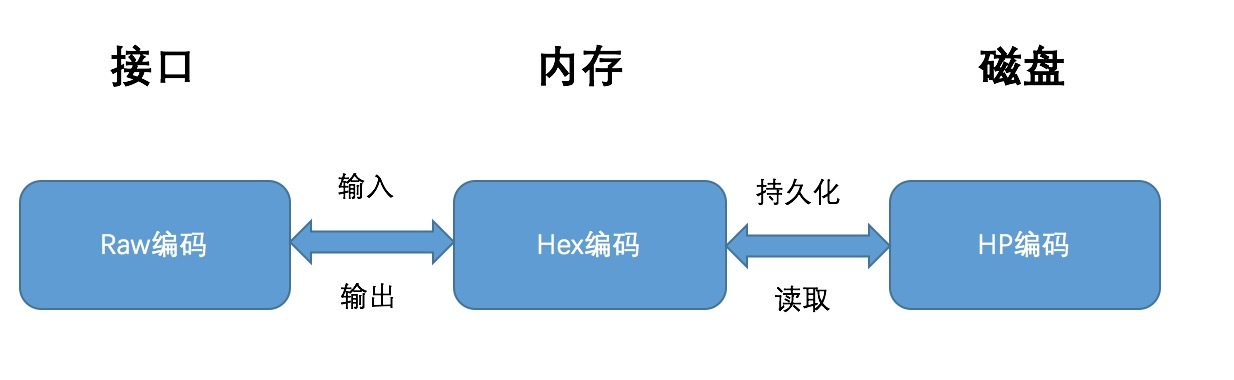
以太坊的MPT树提供了三种不同的编码方式来满足不同场景的不同需求,三种编码方式为;
- Raw编码(原生字符)
- Hex编码(扩展16进制编码)
- Hex-Prefix编码(16进制前缀编码)
三者的关系如下图所示,分别解决的是MPT对外提供接口的编码,在内存中的编码,和持久化到数据库中的编码。
Raw 编码
MPT对外提供的API采用的就是Raw编码方式,这种编码方式不会对key进行修改,如果key是“foo”, value是"bar",编码后的key就是[“f”, “o”, “o”]。
假设我们要把a作为key放入MPT树,key可以直接用a的ASCII表示97就可以了。
Hex 编码
可以发现采用Raw编码以后,从a-z一共26个字母,如果采用分支节点(BranchNode)存储的话需要26个空间,如果再加上0-9一共10个数字和一个value,总共需要37个空间,以太坊的开发者权衡了一下觉得太多了,于是就改良了编码方式,有了Hex编码。
以太坊先定义了一个新单位nibble,一个nibble表示4个bit,0.5个byte。然后按照如下规则编码;
- 将Raw输入的每个字符(1byte)拆分成2个nibble,前4位和后4位各一个nibble;
- 将每个nibble扩展为1个byte(8个bit);
- 然后分别将Raw编码后的十六进制结果的每个b进行如下操作
- b / 16;
- b % 16;
a的ASCII编码为99(十进制),转换十六进制为63
采用Hex编码
[0] = 61 / 16 = 3
[1] = 61 % 16 = 13
编码后的结果 [3, 13]
再举个例子
输入"cat",Raw编码后 [63, 61, 74]
63 / 16 = 3
63 % 16 = 15
61 / 16 = 3
61 % 16 = 13
74 / 16 = 4
74 % 16 = 10
编码后的结果 [3,15,3,13,4,10]
树的最后一位value是一个标识符,如果存储的是真实的数据项,即该节点是叶子节点,则在末尾添加一个ASCII值为16的字符作为终止标识符。添加后的结果是 [3,15,3,13,4,10, 16]
采用Hex编码以后,可以看到原本需要的37个空间存储的消耗都被压缩到了17个空间,横向压缩,但是增加了纵向空间的消耗,是一种工程的妥协。根据Key的数量多少,压缩与否各有优劣。
HP 编码
Hex编码虽然可以压缩空间,但是由于每个字符都是1byte,所以Hex编码的key长度是固定的,如果key长度不确定,那么Hex编码就无能为力了。(Hex-Prefix Encoding 16进制前缀编码) 前面介绍的Hex编码后的数据是在内存中的,如果要对Hex编码后的数据进行持久化,就会发现一个问题,我们对原数据进行了扩展,本来1个byte的数据被我们变成了2个byte,显然这对于存储来说是不可接受的,于是就又有了HP编码。
HP编码的过程如下;
- 输入key(Hex编码的结果)如果有标识符,则去掉这个标识符。
- key的头部填充一个nibble,填充的规则如下
- 如果key的nibble长度是偶数则最后一位0
- 如果key的nibble长度是奇数则最后一位1
- 如果key是扩展节点则倒数第二位是0
- 如果key是叶子节点则倒数第二位是1
例子:nibble长度是奇数的扩展节点填充为0001。
“cat"经过HP编码后的结果 [3,15,3,13,4,10, 16]
再用HP编码
- 去掉16,同时表明这个是叶子节点。
- 叶子节点,nibble数量是奇数个,这两个条件得出需要填充的值为 0010 0000
- 将HP编码后的结果用二进制表示 [0010, 0000,0011, 1111, 0011, 1101, 0100, 1010]
- 将HP编码后的结果合并成byte,为[00100000, 00111111, 00111101, 01001010]转换为十进制是[32, 63, 61, 74]
相较与cat的Raw编码,经过上面的Hex编码和HP编码,既可以能在内存中构建出MPT树,又可以尽可能减小存储所占用的空间,不得不说以太坊设计的巧妙。
安全的MPT
在上面介绍三种编码并没有解决一个问题,如果我们的key非常的长,会导致树非常的深,读写性能急剧的下降,如果有人不怀好意设计了一个独特的key甚至是可以起到DDOS攻击的作用,为了避免上面的问题,以太坊对key进行了一个特别的操作。
将所有的key都进行了一个keccak256(key)的操作,这样就保证了所有key的长度都为一致定长。
持久化MPT
MPT树节点Key的三种编码形式,但是这三种编码都是对key进行的操作,最终持久化到LevelDB中是k-v的形式,还需要对value进行处理。
在以太坊存储键值对之前会采用RLP编码对键值对进行转码,将键值对编码后作为value,计算编码后数据的哈希(keccak256)作为key,存储在levelDB中。
在具体的实现中,为了避免出现相同的key,以太坊会给key增加一些前缀用作区分,比如合约中的MPT树,会增加合约地址,区块数据会增加表示区块的字符和区块号。 MPT树是以太坊非常非常核心的数据结构,在存储区块,交易,交易回执中都有用到,下图展示了MPT树的全貌,可以再感受一下MPT树的精巧。
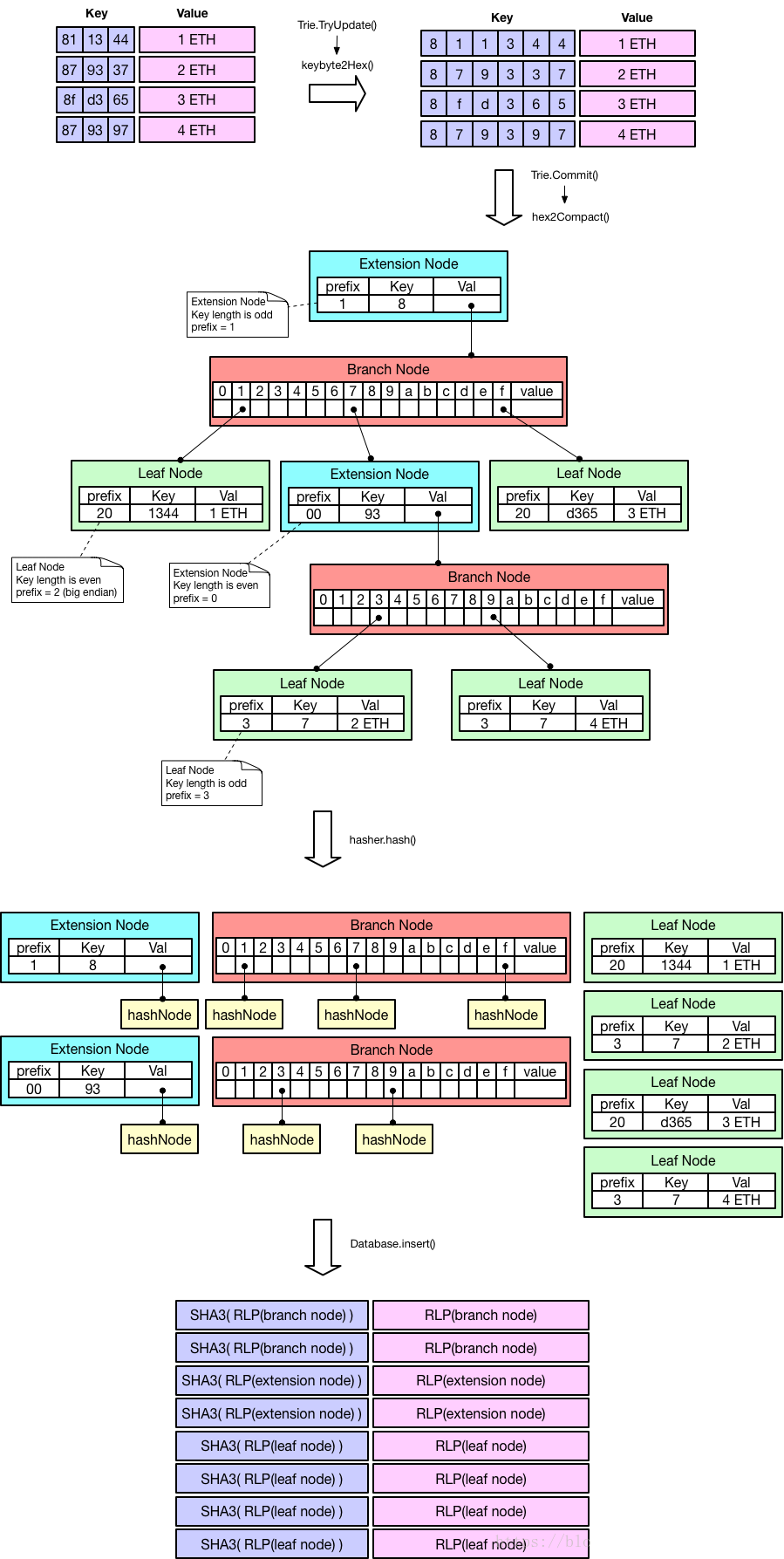
其实随着数据的膨胀,LevelDB本身的读写速度都会变慢,这个是LevelDB实现导致的,这个也是制约MPT树性能的重要因素。