RPC
HTTP 和 RPC
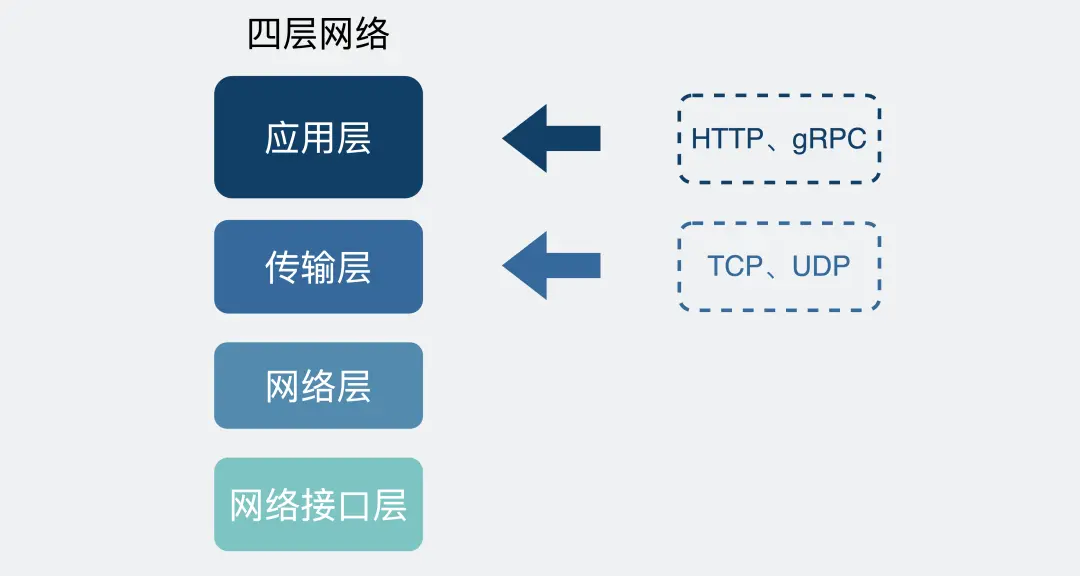
TCP 是传输层的协议,而基于 TCP 造出来的 HTTP 和各类 RPC 协议,它们都只是定义了不同消息格式的应用层协议而已。
HTTP 协议(Hyper Text Transfer Protocol),又叫做超文本传输协议。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。
而 RPC(Remote Procedure Call),又叫做远程过程调用。它本身并不是一个具体的协议,而是一种调用方式。而像 gRPC 和 Thrift 这样的具体实现,才是协议,它们是实现了 RPC 调用的协议。
举个例子,我们平时调用一个本地方法就像下面这样。
res = localFunc(req)如果现在这不是个本地方法,而是个远端服务器暴露出来的一个方法 remoteFunc,如果我们还能像调用本地方法那样去调用它,这样就可以屏蔽掉一些网络细节,用起来更方便,岂不美哉?
res = remoteFunc(req)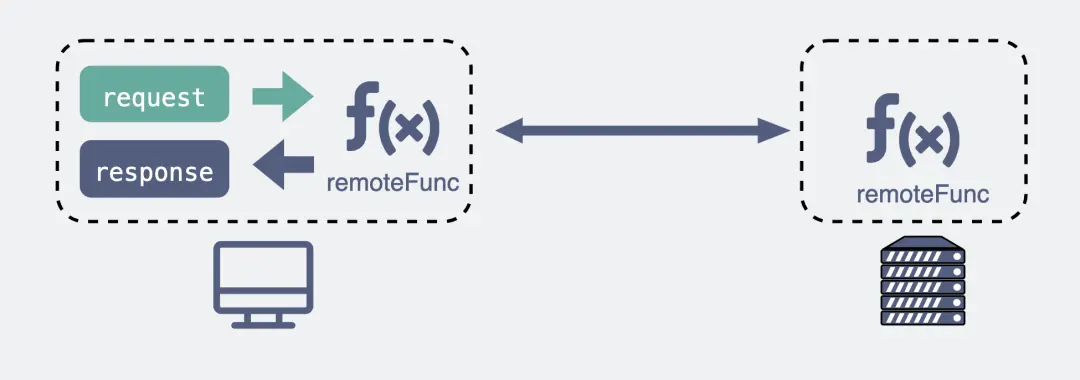
基于这个思路,大佬们造出了非常多款式的 RPC 协议,比如比较有名的gRPC,thrift。
值得注意的是,虽然大部分 RPC 协议底层使用 TCP,但实际上它们不一定非得使用 TCP,改用 UDP 或者 HTTP,其实也可以做到类似的功能。
既然有 HTTP 协议,为什么还要有 RPC?
其实,TCP 是70年代出来的协议,而 HTTP 是 90 年代才开始流行的。而直接使用裸 TCP 会有问题,可想而知,这中间这么多年有多少自定义的协议,而这里面就有80年代出来的 RPC。
所以我们该问的不是既然有 HTTP 协议为什么要有 RPC,而是为什么有 RPC 还要有 HTTP 协议。
现在电脑上装的各种联网软件,比如 xx管家,xx卫士,它们都作为客户端(Client)需要跟服务端(Server)建立连接收发消息,此时都会用到应用层协议,在这种 Client/Server (C/S) 架构下,它们可以使用自家造的 RPC 协议,因为它只管连自己公司的服务器就 ok 了。
但有个软件不同,浏览器(Browser),不管是 Chrome 还是 IE,它们不仅要能访问自家公司的服务器(Server),还需要访问其他公司的网站服务器,因此它们需要有个统一的标准,不然大家没法交流。于是,HTTP 就是那个时代用于统一 Browser/Server (B/S) 的协议。
也就是说在多年以前,HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。很多软件同时支持多端,比如某度云盘,既要支持网页版,还要支持手机端和 PC 端,如果通信协议都用 HTTP 的话,那服务器只用同一套就够了。而 RPC 就开始退居幕后,一般用于公司内部集群里,各个微服务之间的通讯。
那这么说的话,都用 HTTP 得了,还用什么 RPC?
HTTP 和 RPC 有什么区别
服务发现
首先要向某个服务器发起请求,你得先建立连接,而建立连接的前提是,你得知道 IP 地址和端口。这个找到服务对应的 IP 端口的过程,其实就是服务发现。
在 HTTP 中,你知道服务的域名,就可以通过 DNS 服务去解析得到它背后的 IP 地址,默认 80 端口。
而 RPC 的话,就有些区别,一般会有专门的中间服务去保存服务名和IP信息,比如 Consul 或者 Etcd,甚至是 Redis。想要访问某个服务,就去这些中间服务去获得 IP 和端口信息。由于 DNS 也是服务发现的一种,所以也有基于 DNS 去做服务发现的组件,比如CoreDNS。
底层连接形式
以主流的 HTTP/1.1 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接(Keep Alive),之后的请求和响应都会复用这条连接。
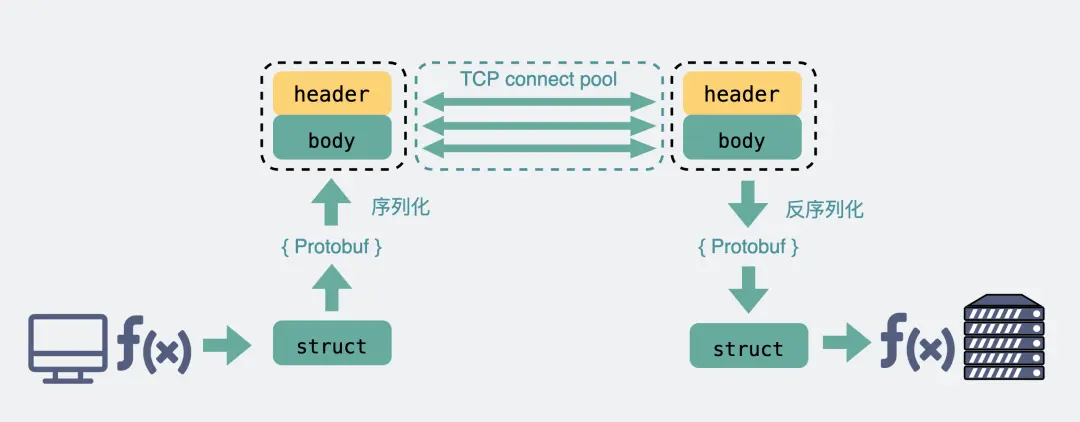
而 RPC 协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 协议一般还会再建个连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。
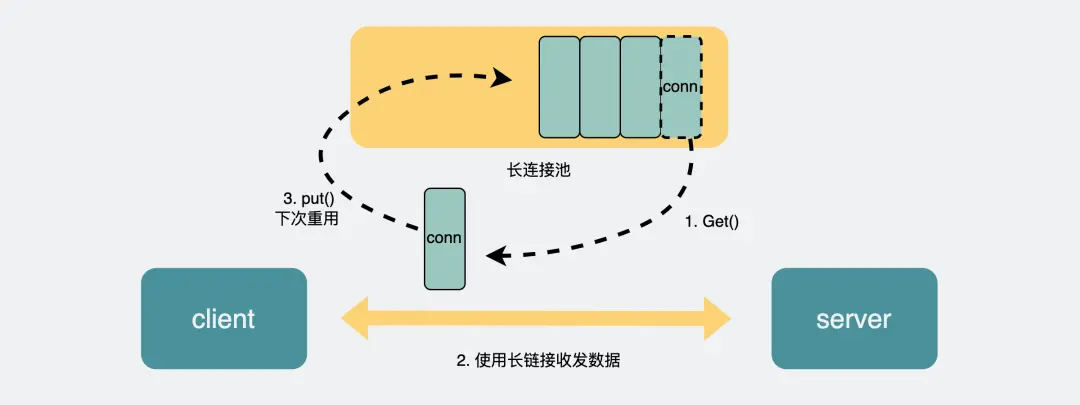
由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 Go 就是这么干的。
传输的内容
基于 TCP 传输的消息,说到底,无非都是消息头 Header 和消息体 Body。
Header 是用于标记一些特殊信息,其中最重要的是消息体长度。
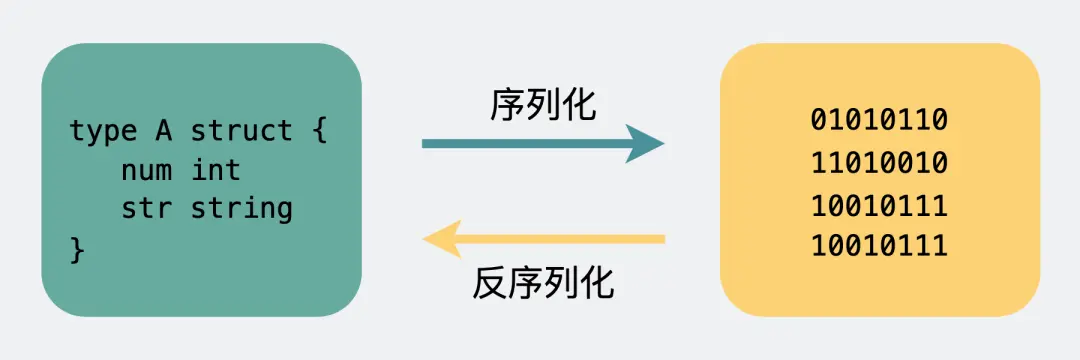
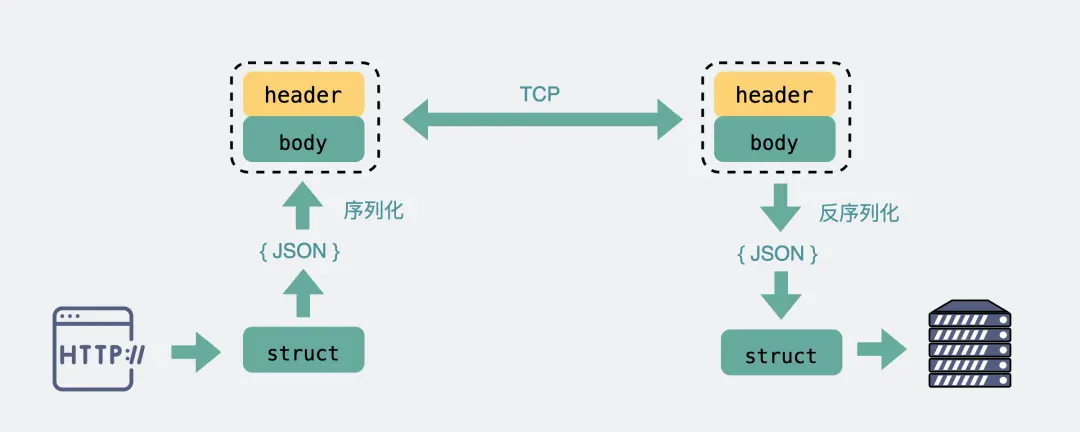
Body 则是放我们真正需要传输的内容,而这些内容只能是二进制 01 串,毕竟计算机只认识这玩意。所以 TCP 传字符串和数字都问题不大,因为字符串可以转成编码再变成 01 串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制 01 串,这样的方案现在也有很多现成的,比如 Json,Protobuf。
这个将结构体转为二进制数组的过程就叫序列化,反过来将二进制数组复原成结构体的过程叫反序列化。
对于主流的 HTTP/1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计初是用于做网页文本展示的,所以它传的内容以字符串为主。Header 和 Body 都是如此。在 Body 这块,它使用 Json 来序列化结构体数据。
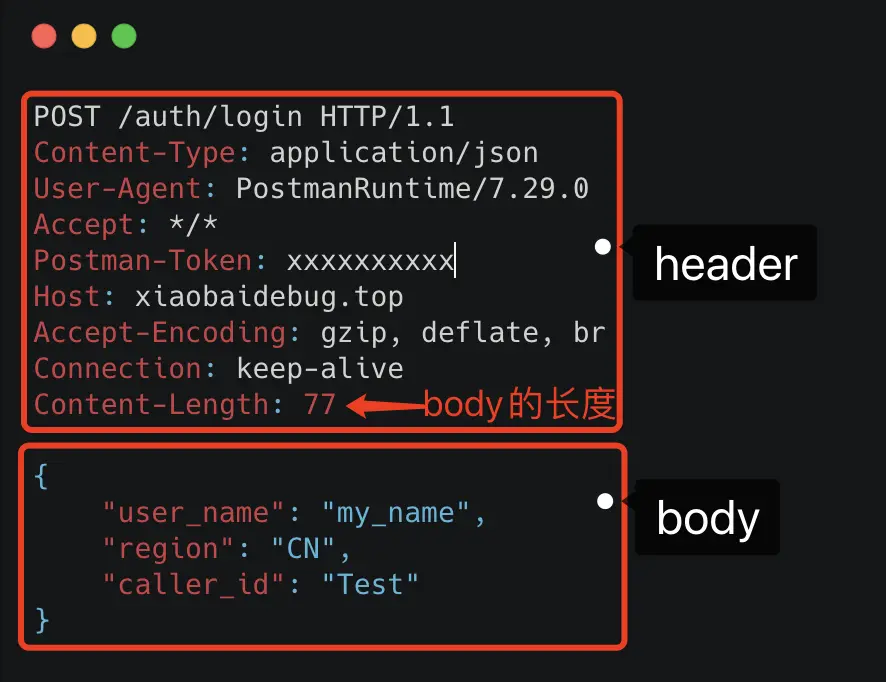
可以看到这里面的内容非常多的冗余。最明显的,像 Header 里的那些信息,其实如果我们约定好头部的第几位是 Content-Type,就不需要每次都真的把"Content-Type"这个字段都传过来,类似的情况其实在 body 的 Json 结构里也特别明显。
而 RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。
当然上面说的 HTTP,其实特指的是现在主流使用的 HTTP/1.1,HTTP/2 在前者的基础上做了很多改进,所以性能可能比很多 RPC 协议还要好,甚至连 gRPC 底层都直接用的 HTTP/2。
那么问题又来了,为什么既然有了 HTTP/2,还要有 RPC 协议?
这个是由于 HTTP/2 是 2015 年出来的。那时候很多公司内部的 RPC 协议都已经跑了好些年了,基于历史原因,一般也没必要去换了。
RPC 是一个概念泛指调用远程的函数,HTTP 是一个协议,想实现 RPC 也可以基于 HTTP 协议。
而一般语境中的 RPC 可以理解为 gRPC 这种 RPC 框架,它对比起纯 HTTP 协议传输数据来说,这类框架会对编解码和网络层有特殊的优化,从而有更高的效率。
所以哪怕 HTTP/2 或 HTTP/3 完全普及(性能上碾压),也不会取代 RPC,因为它本质上就是个泛指调用远程函数的概念,很多框架依旧可以基于高性能的 HTTP/2 或 3 去实现新的 RPC 框架。