Pool
Go 是一个自动垃圾回收的编程语言,采用三色并发标记算法标记对象并回收。和其它没有自动垃圾回收的编程语言不同,使用 Go 语言创建对象的时候,我们没有回收 / 释放的心理负担,想用就用,想创建就创建。
但是,如果你想使用 Go 开发一个高性能的应用程序的话,就必须考虑垃圾回收给性能带来的影响,毕竟,Go 的自动垃圾回收机制还是有一个 STW(stop-the-world,程序暂停)的时间,而且,大量地创建在堆上的对象,也会影响垃圾回收标记的时间。
所以,一般我们做性能优化的时候,会采用对象池的方式,把不用的对象回收起来,避免被垃圾回收掉,这样使用的时候就不必在堆上重新创建了。
不止如此,像数据库连接、TCP 的长连接,这些连接在创建的时候是一个非常耗时的操作。如果每次都创建一个新的连接对象,耗时较长,很可能整个业务的大部分耗时都花在了创建连接上。所以,如果我们能把这些连接保存下来,避免每次使用的时候都重新创建,不仅可以大大减少业务的耗时,还能提高应用程序的整体性能。
sync.Pool
Go 标准库中提供了一个通用的 Pool 数据结构,也就是 sync.Pool,我们使用它可以创建池化的对象。不过,这个类型也有一些使用起来不太方便的地方,就是它池化的对象可能会被垃圾回收掉,这对于数据库长连接等场景是不合适的。
sync.Pool 数据类型用来保存一组可独立访问的临时对象。“临时”说明了 sync.Pool 这个数据类型的特点,也就是说,它池化的对象会在未来的某个时候被毫无预兆地移除掉。而且,如果没有别的对象引用这个被移除的对象的话,这个被移除的对象就会被垃圾回收掉。
因为 Pool 可以有效地减少新对象的申请,从而提高程序性能,所以 Go 内部库也用到了 sync.Pool,比如 fmt 包,它会使用一个动态大小的 buffer 池做输出缓存,当大量的 goroutine 并发输出的时候,就会创建比较多的 buffer,并且在不需要的时候回收掉。
- sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象;
- sync.Pool 不可在使用之后再复制使用。
数据结构
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() any
}对于同一个 sync.Pool ,它在每个 P 上都分配了一个本地对象池 poolLocal。
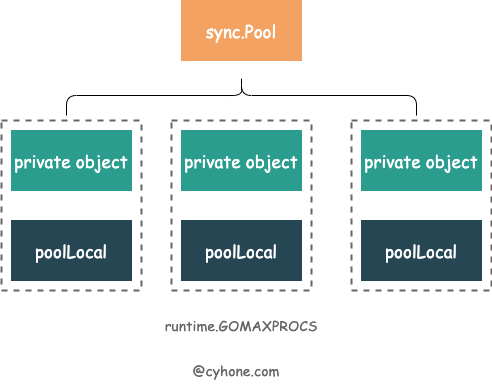
其中,我们需要着重关注以下三个字段:
local是个数组,长度为 P 的个数。其元素类型是poolLocal。这里面存储着各个 P 对应的本地对象池。可以近似的看做[P]poolLocal。localSize。代表 local 数组的长度。因为 P 可以在运行时通过调用 runtime.GOMAXPROCS 进行修改, 因此我们还是得通过localSize来对应local数组的长度。
其实,这个数据类型不难,它只提供了三个对外的方法:New、Get 和 Put。
- New
Pool struct 包含一个 New 字段,这个字段的类型是函数 func() any。当调用 Pool 的 Get 方法从池中获取元素,没有更多的空闲元素可返回时,就会调用这个 New 方法来创建新的元素。如果你没有设置 New 字段,没有更多的空闲元素可返回时,Get 方法将返回 nil,表明当前没有可用的元素。
New 是可变的字段。这就意味着,你可以在程序运行的时候改变创建元素的方法。当然,很少有人会这么做,因为一般我们创建元素的逻辑都是一致的,要创建的也是同一类的元素,所以你在使用 Pool 的时候也没必要玩一些“花活”,在程序运行时更改 New 的值。
- Get
如果调用这个方法,就会从 Pool取走一个元素,这也就意味着,这个元素会从 Pool 中移除,返回给调用者。不过,除了返回值是正常实例化的元素,Get 方法的返回值还可能会是一个 nil(Pool.New 字段没有设置,又没有空闲元素可以返回),所以你在使用的时候,可能需要判断。
- Put
这个方法用于将一个元素返还给 Pool,Pool 会把这个元素保存到池中,并且可以复用。但如果 Put 一个 nil 值,Pool 就会忽略这个值。
由于每个 P 都有自己的一个本地对象池 poolLocal,Get 和 Put 操作都会优先存取本地对象池。由于 P 的特性,操作本地对象池的时候整个并发问题就简化了很多,可以尽量避免并发冲突。
// Local per-P Pool appendix.
type poolLocalInternal struct {
private any // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}private私有变量。Get 和 Put 操作都会优先存取 private 变量,如果 private 变量可以满足情况,则不再深入进行其他的复杂操作。shared。其类型为 poolChain,从名字不难看出这个是链表结构,这个就是 P 的本地对象池了。
poolChain 的实现
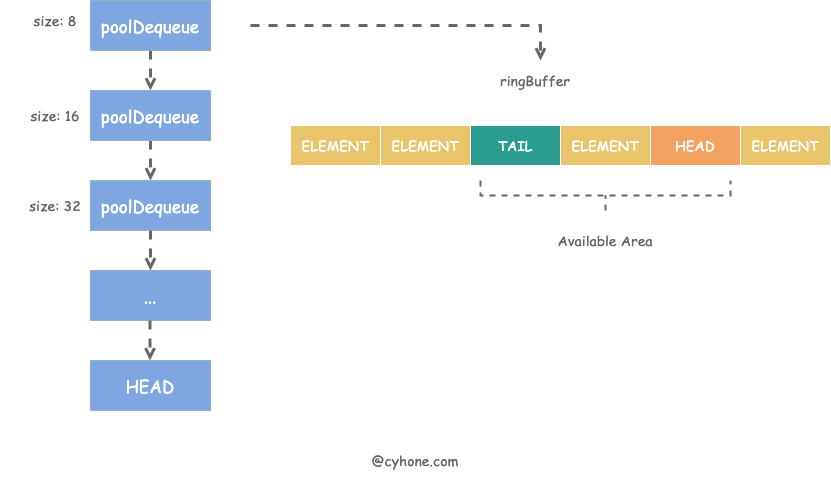
poolChain 是个链表结构,其链表头 HEAD 指向最新分配的元素项。链表中的每一项是一个 poolDequeue 对象。poolDequeue 本质上是一个 ring buffer 结构。
type poolChain struct {
// head is the poolDequeue to push to. This is only accessed
// by the producer, so doesn't need to be synchronized.
head *poolChainElt
// tail is the poolDequeue to popTail from. This is accessed
// by consumers, so reads and writes must be atomic.
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
// next and prev link to the adjacent poolChainElts in this
// poolChain.
//
// next is written atomically by the producer and read
// atomically by the consumer. It only transitions from nil to
// non-nil.
//
// prev is written atomically by the consumer and read
// atomically by the producer. It only transitions from
// non-nil to nil.
next, prev *poolChainElt
}
type poolDequeue struct {
// headTail packs together a 32-bit head index and a 32-bit
// tail index. Both are indexes into vals modulo len(vals)-1.
//
// tail = index of oldest data in queue
// head = index of next slot to fill
//
// Slots in the range [tail, head) are owned by consumers.
// A consumer continues to own a slot outside this range until
// it nils the slot, at which point ownership passes to the
// producer.
//
// The head index is stored in the most-significant bits so
// that we can atomically add to it and the overflow is
// harmless.
headTail atomic.Uint64
// vals is a ring buffer of interface{} values stored in this
// dequeue. The size of this must be a power of 2.
//
// vals[i].typ is nil if the slot is empty and non-nil
// otherwise. A slot is still in use until *both* the tail
// index has moved beyond it and typ has been set to nil. This
// is set to nil atomically by the consumer and read
// atomically by the producer.
vals []eface
}使用 ring buffer 是因为它有以下优点:
- 预先分配好内存,且分配的内存项可不断复用。
- 由于ring buffer 本质上是个数组,是连续内存结构,非常利于 CPU Cache。在访问poolDequeue 某一项时,其附近的数据项都有可能加载到统一 Cache Line 中,访问速度更快。
我们再注意看一个细节,poolDequeue 作为一个 ring buffer,自然需要记录下其 head 和 tail 的值。但在 poolDequeue 的定义中,head 和 tail 并不是独立的两个变量,只有一个 uint64 的 headTail 变量。
这是因为 headTail 变量将 head 和 tail 打包在了一起:其中高 32 位是 head 变量,低 32 位是 tail 变量。如下图所示:

对于一个 poolDequeue 来说,可能会被多个 P 同时访问,这个时候就会带来并发问题。
例如:当 ring buffer 空间仅剩一个的时候,即 head - tail = 1。 如果多个 P 同时访问 ring buffer,在没有任何并发措施的情况下,两个 P 都可能会拿到对象,这肯定是不符合预期的。
在不引入 Mutex 锁的前提下,sync.Pool 是怎么实现的呢?sync.Pool 利用了 atomic 包中的 CAS 操作。两个 P 都可能会拿到对象,但在最终设置 headTail 的时候,只会有一个 P 调用 CAS 成功,另外一个 CAS 失败。
atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2)在更新 head 和 tail 的时候,也是通过原子变量 + 位运算进行操作的。例如,当实现 head++ 的时候,需要通过以下代码实现:
const dequeueBits = 32
atomic.AddUint64(&d.headTail, 1<<dequeueBits)buffer 池
好了,了解了这几个方法,下面我们看看 sync.Pool 最常用的一个场景:buffer 池(缓冲池)。
因为 byte slice 是经常被创建销毁的一类对象,使用 buffer 池可以缓存已经创建的 byte slice,比如,著名的静态网站生成工具 Hugo 中,就包含这样的实现 bufpool,你可以看一下下面这段代码:
var buffers = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func GetBuffer() *bytes.Buffer {
return buffers.Get().(*bytes.Buffer)
}
func PutBuffer(buf *bytes.Buffer) {
buf.Reset()
buffers.Put(buf)
}除了 Hugo,这段 buffer 池的代码非常常用。很可能你在阅读其它项目的代码的时候就碰到过,或者是你自己实现 buffer 池的时候也会这么去实现,但是请你注意了,这段代码是有问题的,你一定不要将上面的代码应用到实际的产品中。它可能会有内存泄漏的问题,下面我会重点讲这个问题。
实现原理
Go 1.13 之前的 sync.Pool 的实现有 2 大问题:
- 每次 GC 都会回收创建的对象。
如果缓存元素数量太多,就会导致 STW 耗时变长;缓存元素都被回收后,会导致 Get 命中率下降,Get 方法不得不新创建很多对象。
- 底层实现使用了 Mutex,对这个锁并发请求竞争激烈的时候,会导致性能的下降。
在 Go 1.13 中,sync.Pool 做了大量的优化。提高并发程序性能的优化点是尽量不要使用锁,如果不得已使用了锁,就把锁 Go 的粒度降到最低。Go 对 Pool 的优化就是避免使用锁,同时将加锁的 queue 改成 lock-free 的 queue 的实现,给即将移除的元素再多一次“复活”的机会。
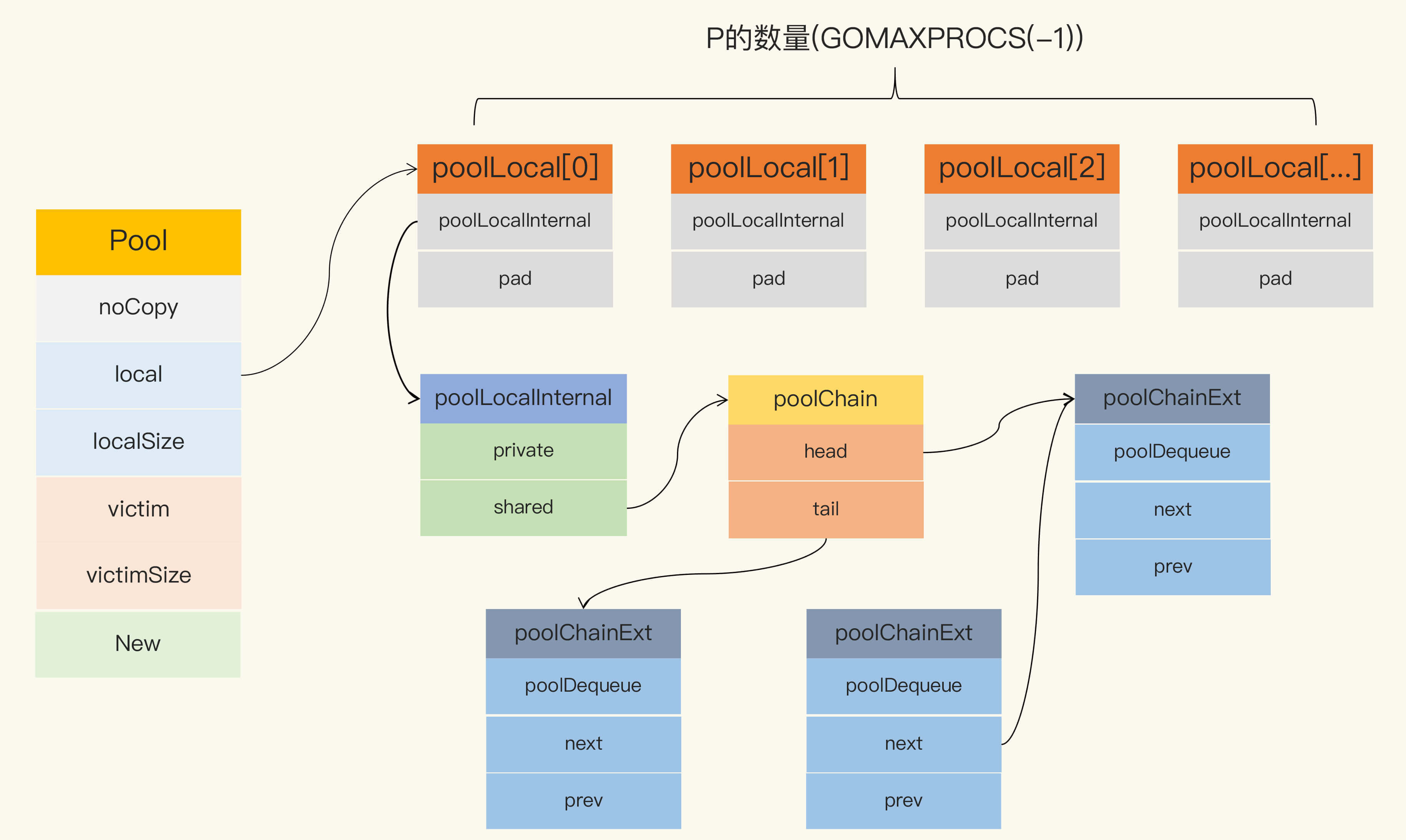
Pool 最重要的两个字段是 local 和 victim,因为它们两个主要用来存储空闲的元素。
每次垃圾回收的时候,Pool 会把 victim 中的对象移除,然后把 local 的数据给 victim,这样的话,local 就会被清空,而 victim 就像一个垃圾分拣站,里面的东西可能会被当做垃圾丢弃了,但是里面有用的东西也可能被捡回来重新使用。
victim 中的元素如果被 Get 取走,那么这个元素就很幸运,因为它又“活”过来了。但是,如果这个时候 Get 的并发不是很大,元素没有被 Get 取走,那么就会被移除掉,因为没有别人引用它的话,就会被垃圾回收掉。
下面的代码是垃圾回收时 sync.Pool 的处理逻辑:
func poolCleanup() {
// 丢弃当前victim, STW所以不用加锁
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// 将local复制给victim, 并将原local置为nil
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}在这段代码中,你需要关注一下 local 字段,因为所有当前主要的空闲可用的元素都存放在 local 字段中,请求元素时也是优先从 local 字段中查找可用的元素。local 字段包含一个 poolLocalInternal 字段,并提供 CPU 缓存对齐,从而避免 false sharing。
而 poolLocalInternal 也包含两个字段:private 和 shared。
- private,代表一个缓存的元素,而且只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,所以不会有并发的问题。
- shared,可以由任意的 P 访问,但是只有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相当于只有一个本地的 P 作为生产者(Producer),多个 P 作为消费者(Consumer),它是使用一个 local-free 的 queue 列表实现的。
Get 方法
func (p *Pool) Get() interface{} {
// 把当前goroutine固定在当前的P上
l, pid := p.pin()
x := l.private // 优先从local的private字段取,快速
l.private = nil
if x == nil {
// 从当前的local.shared弹出一个,注意是从head读取并移除
x, _ = l.shared.popHead()
if x == nil { // 如果没有,则去偷一个
x = p.getSlow(pid)
}
}
runtime_procUnpin()
// 如果没有获取到,尝试使用New函数生成一个新的
if x == nil && p.New != nil {
x = p.New()
}
return x
}首先,从本地的 private 字段中获取可用元素,因为没有锁,获取元素的过程会非常快,如果没有获取到,就尝试从本地的 shared 获取一个,如果还没有,会使用 getSlow 方法去其它的 shared 中“偷”一个。最后,如果没有获取到,就尝试使用 New 函数创建一个新的。
这里的重点是 getSlow 方法,我们来分析下。看名字也就知道了,它的耗时可能比较长。它首先要遍历所有的 local,尝试从它们的 shared 弹出一个元素。如果还没找到一个,那么,就开始对 victim 下手了。
在 vintim 中查询可用元素的逻辑还是一样的,先从对应的 victim 的 private 查找,如果查不到,就再从其它 victim 的 shared 中查找。
func (p *Pool) getSlow(pid int) interface{} {
size := atomic.LoadUintptr(&p.localSize)
locals := p.local
// 从其它proc中尝试偷取一个元素
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 如果其它proc也没有可用元素,那么尝试从vintim中获取
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil { // 同样的逻辑,先从vintim中的local private获取
l.private = nil
return x
}
for i := 0; i < int(size); i++ { // 从vintim其它proc尝试偷取
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 如果victim中都没有,则把这个victim标记为空,以后的查找可以快速跳过了
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}这里我没列出 pin 代码的实现,你只需要知道,pin 方法会将此 goroutine 固定在当前的 P 上,避免查找元素期间被其它的 P 执行。固定的好处就是查找元素期间直接得到跟这个 P 相关的 local。有一点需要注意的是,pin 方法在执行的时候,如果跟这个 P 相关的 local 还没有创建,或者运行时 P 的数量被修改了的话,就会新创建 local。
Put 方法
func (p *Pool) Put(x interface{}) {
if x == nil { // nil值直接丢弃
return
}
l, _ := p.pin()
if l.private == nil { // 如果本地private没有值,直接设置这个值即可
l.private = x
x = nil
}
if x != nil { // 否则加入到本地队列中
l.shared.pushHead(x)
}
runtime_procUnpin()
}Put 的逻辑相对简单,优先设置本地 private,如果 private 字段已经有值了,那么就把此元素 push 到本地队列中。
小结
- 利用 GMP 的特性,为每个 P 创建了一个本地对象池 poolLocal,尽量减少并发冲突。
- 每个 poolLocal 都有一个 private 对象,优先存取 private 对象,可以避免进入复杂逻辑。
- 在 Get 和 Put 期间,利用
pin锁定当前 P,防止 goroutine 被抢占,造成程序混乱。 - 在获取对象期间,利用对象窃取的机制,从其他 P 的本地对象池以及 victim 中获取对象。
- 充分利用 CPU Cache 特性,提升程序性能。
sync.Pool 的坑
内存泄漏
可以使用 sync.Pool 做 buffer 池,但是,如果用刚刚的那种方式做 buffer 池的话,可能会有内存泄漏的风险。为啥这么说呢?我们来分析一下。
取出来的 bytes.Buffer 在使用的时候,我们可以往这个元素中增加大量的 byte 数据,这会导致底层的 byte slice 的容量可能会变得很大。这个时候,即使 Reset 再放回到池子中,这些 byte slice 的容量不会改变,所占的空间依然很大。而且,因为 Pool 回收的机制,这些大的 Buffer 可能不被回收,而是会一直占用很大的空间,这属于内存泄漏的问题。
即使是 Go 的标准库,在内存泄漏这个问题上也栽了几次坑,比如 issue 23199、@dsnet提供了一个简单的可重现的例子,演示了内存泄漏的问题。再比如 encoding、json 中类似的问题:将容量已经变得很大的 Buffer 再放回 Pool 中,导致内存泄漏。后来在元素放回时,增加了检查逻辑,改成放回的超过一定大小的 buffer,就直接丢弃掉,不再放到池子中,如下所示:
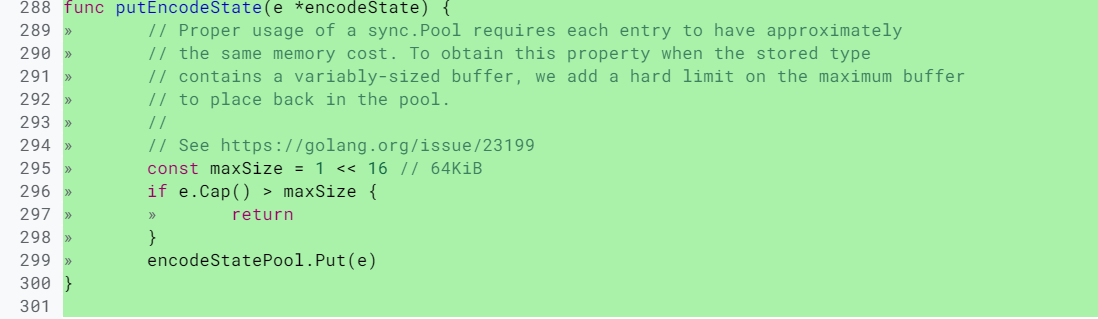
package fmt 中也有这个问题,修改方法是一样的,超过一定大小的 buffer,就直接丢弃了:
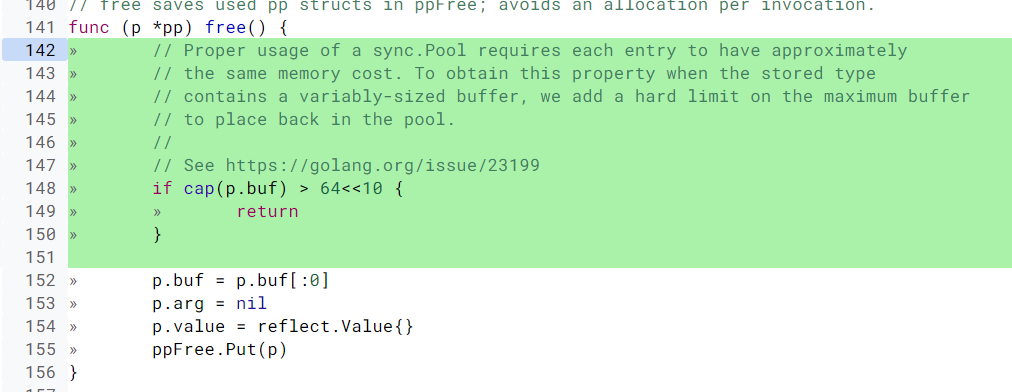
在使用 sync.Pool 回收 buffer 的时候,一定要检查回收的对象的大小。如果 buffer 太大,就不要回收了,否则就太浪费了。
对于有固定大小的对象,并不需要太过注意放入sync.Pool中对象的大小,这种场景出现内存泄漏的可能性小之又小。但是,如果放入 sync.Pool 中的对象存在自动扩容的机制,如果不注意放入 sync.Pool 中对象的大小,此时将很有可能导致内存泄漏。
内存浪费
除了内存泄漏以外,还有一种浪费的情况,就是池子中的 buffer 都比较大,但在实际使用的时候,很多时候只需要一个小的 buffer,这也是一种浪费现象。接下来,我就讲解一下这种情况的处理方法。
要做到物尽其用,尽可能不浪费的话,我们可以将 buffer 池分成几层。首先,小于 512 byte 的元素的 buffer 占一个池子;其次,小于 1K byte 大小的元素占一个池子;再次,小于 4K byte 大小的元素占一个池子。这样分成几个池子以后,就可以根据需要,到所需大小的池子中获取 buffer 了。
在标准库 net/http/server.go中的代码中,就提供了 2K 和 4K 两个 writer 的池子。你可以看看下面这段代码:
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
var copyBufPool = sync.Pool{
New: func() interface{} {
b := make([]byte, 32*1024)
return &b
},
}
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2 << 10:
return &bufioWriter2kPool
case 4 << 10:
return &bufioWriter4kPool
}
return nil
}YouTube 开源的知名项目 vitess 中提供了 bucketpool 的实现,它提供了更加通用的多层 buffer 池。你在使用的时候,只需要指定池子的最大和最小尺寸,vitess 就会自动计算出合适的池子数。而且,当你调用 Get 方法的时候,只需要传入你要获取的 buffer 的大小,就可以了。下面这段代码就描述了这个过程,你可以看看:
// Pool is actually multiple pools which store buffers of specific size.
// i.e. it can be three pools which return buffers 32K, 64K and 128K.
type Pool struct {
minSize int
maxSize int
pools []*sizedPool
}第三方库
这是 fasthttp 作者 valyala 提供的一个 buffer 池,基本功能和 sync.Pool 相同。它的底层也是使用 sync.Pool 实现的,包括会检测最大的 buffer,超过最大尺寸的 buffer,就会被丢弃。
它提供了校准(calibrate,用来动态调整创建元素的权重)的机制,可以“智能”地调整 Pool 的 defaultSize 和 maxSize。一般来说,我们使用 buffer size 的场景比较固定,所用 buffer 的大小会集中在某个范围里。有了校准的特性,bytebufferpool 就能够偏重于创建这个范围大小的 buffer,从而节省空间。