切片
Slice依托数组实现,底层数组对用户屏蔽,在底层数组容量不足时可以实现自动重分配并生成新的Slice。
切片的长度可以自动地随着其中元素数量的增长而增长,但不会随着元素数量的减少而减小。
数据结构
// src/runtime/slice.go
type slice struct {
array unsafe.Pointer // 引用着底层存储在间接部分上的元素(指向底层的数组的指针)
len int // 长度
cap int // 容量
}由数据结构可以看出来,一个切片是由一个直接部分和一个可能的被此直接部分引用着的间接部分组成。切片中的所有元素同样也是紧挨着存放在一块连续的内存中(底层是数组),也就是间接部分。
所有切片类型的尺寸都是一致的。两个 int + 一个指针大小。切片类型属于不可比较类型,任意两个切片值是不能相互比较的。但是一个切片值可以和预声明的nil标识符进行比较以检查此切片值是否为一个零值。
下面这张图描绘了一个切片值的内存布局。
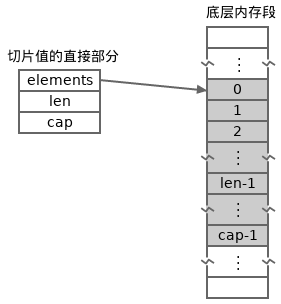
尽管一个切片值的底层元素部分可能位于一个比较大的内存片段上,但是此切片值只能感知到此内存片段上的一个子片段。 比如,上图中的切片值只能感知到灰色的子片段。
在上图中,从下标len(包含)到下标cap(不包含)对应的元素并不属于图中所示的切片值。 它们只是此切片之中的一些冗余元素槽位,但是它们可能是其它切片(或者数组)值中的有效元素。
声明以及初始化
var s []int // nil 切片
初值为零值 nil 的切片类型变量,可以借助内置的 append 的函数进行操作,这种在 Go 语言中被称为零值可用。
使用字面量初始化新的切片
s = []int{1,2,3}切片中索引和数组中索引的要求是一致的,可参考数组。
var a uint = 1
var _ = [5]int{a: 100} // error: 下标必须为常量
[]T{}表示类型[]T的一个空切片值,它和[]T(nil)是不等价的
当我们使用字面量 []int{1, 2, 3} 创建新的切片时,编译器会在编译期间将它展开如下所示的代码片段:
var vstat [3]int
vstat[0] = 1
vstat[1] = 2
vstat[2] = 3
var vauto *[3]int = new([3]int)
*vauto = vstat
slice := vauto[:]- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组
- 将这些字面量元素存储到初始化的数组中
- 创建一个同样指向 [3]int 类型的数组指针
- 将静态存储区的数组 vstat 赋值给 vauto 指针所在的地址;
- 通过 [:] 操作获取一个底层使用 vauto 的切片
最后一步的 [:] 就是使用下标创建切片的方法,从这一点我们也能看出 [:] 操作是创建切片最底层的一种方法。
使用数组或者切片(下标)创建切片
a := [5]int{1,2,3,4,5}
s1 := a[0:3]
s2 := s1[0:2]使用下标创建切片是最原始也最接近汇编语言的方式,它是所有方法中最为底层的一种,编译器会将 arr[0:3] 或者 slice[0:3] 等语句转换成 OpSliceMake 操作。
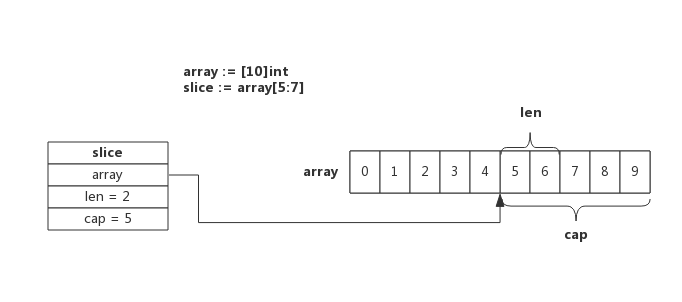
使用下标初始化切片不会拷贝原数组或者原切片中的数据,它只会创建一个指向原数组(切片)的切片结构体,所以修改新切片的数据也会修改原数组(切片)。 即新切片和原数组共享一部分内存。
Q: 为什么不说新切片和原切片共享一部分内存呢?
A: 因为原切片也是和底层数组共享内存。
切片从数组array[5]开始,到数组array[7]结束(不含array[7]),即切片长度为2,数组后面的内容都作为切片的预留内存,即capacity为5。
实际上,Go中有两种取子切片的语法形式(假设baseContainer是一个切片或者数组):
baseContainer[low : high] // 双下标形式
baseContainer[low : high : max] // 三下标形式
上面所示的双下标形式等价于下面的三下标形式:
baseContainer[low : high : cap(baseContainer)]上面所示的取子切片表达式的语法形式中的下标必须满足下列关系,否则代码要么编译不通过,要么在运行时刻将造成panic。
// 双下标形式
0 <= low <= high <= cap(baseContainer)
// 三下标形式
0 <= low <= high <= max <= cap(baseContainer)如果baseContainer是一个零值nil切片,只要上面所示的子切片表达式中下标的值均为0,则这两个子切片表达式不会造成panic。 在这种情况下,结果切片也是一个nil切片。
子切片表达式的结果切片的长度为high - low、容量为max - low。 派生出来的结果切片的长度可能大于基础切片的长度,但结果切片的容量绝不可能大于基础切片的容量。
在实践中,我们常常在子切片表达式中省略若干下标,以使代码看上去更加简洁。省略规则如下:
- 如果下标
low为零,则它可被省略。此条规则同时适用于双下标形式和三下标形式。 - 如果下标
high等于len(baseContainer),则它可被省略。此条规则只适用于双下标形式。 - 三下标形式中的下标
max在任何情况下都不可被省略。
package main
import "fmt"
func main() {
a := [...]int{0, 1, 2, 3, 4, 5, 6}
s0 := a[:] // <=> s0 := a[0:7:7]
s1 := s0[:] // <=> s1 := s0
s2 := s1[1:3] // <=> s2 := a[1:3]
s3 := s1[3:] // <=> s3 := s1[3:7]
s4 := s0[3:5] // <=> s4 := s0[3:5:7]
s5 := s4[:2:2] // <=> s5 := s0[3:5:5]
s6 := append(s4, 77)
s7 := append(s5, 88)
s8 := append(s7, 66)
s3[1] = 99
fmt.Println(len(s2), cap(s2), s2) // 2 6 [1 2]
fmt.Println(len(s3), cap(s3), s3) // 4 4 [3 99 77 6]
fmt.Println(len(s4), cap(s4), s4) // 2 4 [3 99]
fmt.Println(len(s5), cap(s5), s5) // 2 2 [3 99]
fmt.Println(len(s6), cap(s6), s6) // 3 4 [3 99 77]
fmt.Println(len(s7), cap(s7), s7) // 3 4 [3 4 88]
fmt.Println(len(s8), cap(s8), s8) // 4 4 [3 4 88 66]
}下面这张图描绘了上面的程序在退出之前各个数组和切片的状态。
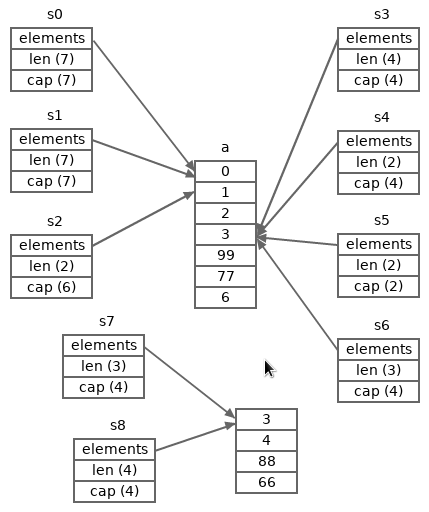
从这张图片可以看出,切片s7和s8共享存储它们的元素的底层内存片段,其它切片和数组a共享同一个存储元素的内存片段。
请注意,子切片操作有可能会造成暂时性的内存泄露。 比如,下面在这个函数中开辟的内存块中的前50个元素槽位在它的调用返回之后将不再可见。 这50个元素槽位所占内存浪费了,这属于暂时性的内存泄露。 当这个函数中开辟的内存块今后不再被任何切片所引用,此内存块将被回收,这时内存才不再继续泄漏。
func f() []int {
s := make([]int, 10, 100)
return s[50:60]
}请注意,在上面这个函数中,子切片表达式中的起始下标(50)比s的长度(10)要大,这是允许的。
使用 make创建切片
使用make来创建Slice时,可以同时指定长度和容量,创建时底层会分配一个数组,数组的长度即容量。
make(S, length, capacity)
make(S, length) // <=> make(S, length, length)
具体如下:
s := make([]int,5,10)如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 会被直接转换成如下所示的代码:
var arr [4]int // 等于创建了一个 [4]int{0,0,0,0} 的底层数组
n := arr[:3]上述代码会初始化数组并通过下标 [:3] 得到数组对应的切片,这两部分操作都会在编译阶段完成,编译器会在栈上或者静态存储区创建数组并将 [:3] 转换成上一节提到的 OpSliceMake 操作。
当切片发生逃逸或者非常大时,运行时需要 runtime.makeslice 在堆上初始化切片,该函数仅会返回指向底层数组的指针:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}上述函数的主要工作是计算切片占用的内存空间并在堆上申请一片连续的内存。
runtime.makeslice 在最后调用的 runtime.mallocgc 是用于申请内存的函数,这个函数的实现还是比较复杂,如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的对象会在堆上初始化。
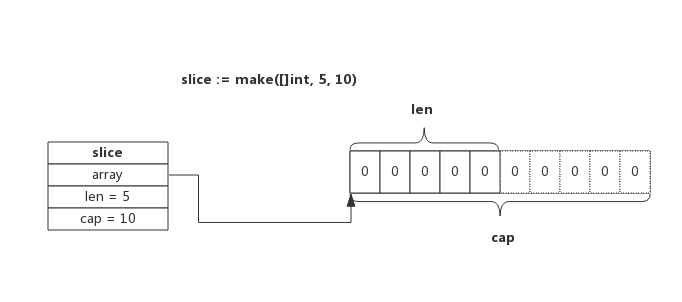
该Slice长度为5,即可以使用下标slice[0] ~ slice[4]来操作里面的元素,capacity为10,表示后续向slice添加新的元素时可以不必重新分配内存,直接使用预留内存即可。
使用make函数创建的切片中的所有元素值均被初始化为(结果切片的元素类型的)零值。
使用 new 创建切片
内置new函数可以用来为一个任何类型的值开辟内存并返回一个存储有此值的地址的指针。 用new函数开辟出来的值均为零值。因为这个原因,new函数对于创建映射和切片值来说没有任何价值。
使用new函数来用来创建数组值并非是完全没有意义的,但是在实践中很少这么做,因为使用组合字面量来创建数组值更为方便。
空切片是否分配了底层数组
var s = []int{} 空切片是否也有底层数组?这个数组是什么样的呢?
var s1 = []int{}
p1 := (*reflect.SliceHeader)(unsafe.Pointer(&s1))
fmt.Printf("empty slice's header is %#v\n", *p1)
var s2 []int
p2 := (*reflect.SliceHeader)(unsafe.Pointer(&s2))
fmt.Printf("nil slice's header is %#v\n", *p2)运行:
empty slice's header is reflect.SliceHeader{Data:0xc000065f08, Len:0, Cap:0}
nil slice's header is reflect.SliceHeader{Data:0x0, Len:0, Cap:0}我们看到nil切片在运行时表示的三个字段值都是0;而空切片的len、cap值为0,但data值不为零。
答案是肯定的:没有分配!那么上述代码中空切片在运行时表示中第一个字段data的值0xc000065f08从何而来,难道不是底层数组的地址么?
经过一系列汇编分析,切片s1的指向底层数组的指针data的值实际上是一个栈上的内存单元的地址,Go编译器并没有在堆上额外分配新的内存空间作为切片s1的底层数组。至于这个栈上内存单元是干嘛的,不清楚。
切片的地址
同数组不同的是,一个切片的变量名取地址和这个切片下标为0的元素不是同一个地址,这也可以由切片的底层数据结构得出这个结论。即切片本身是持有一个数组指针的结构体。
s := []int{1, 2}
fmt.Printf("s: %p\n", &s) // s: 0xc0000084e0 切片的直接值部的地址
fmt.Printf("s[0]: %p\n", &s[0]) // s[0]: 0xc00000a660 切片的底层数组地址
赋值
在 Go 语言中所有的赋值操作均是源值被复制给了目标值。精确地说,源值的直接部分复制给了目标值。
注意:函数传参和结果返回其实都是赋值。
所以切片的赋值操作,等于把源值切片结构体中三个字段挨个复制给目标切片中的三个字段,也就是 底层数组的指针(地址) 被复制过去了,从而赋值就是共享了底层的数组。
当一个切片赋值给另一个切片后,它们将共享底层的元素。它们的长度和容量也相等。如果以后其中一个切片改变了长度或者容量,此变化不会体现到另一个切片中。
内置函数 copy
我们可以使用内置copy函数来将一个切片中的元素复制到另一个切片。copy函数的第一个参数为目标切片,第二个参数为源切片。 传递给一个copy函数调用的两个实参可以共享一些底层元素。 copy函数返回复制了多少个元素,拷贝数量取两个切片长度的最小值,即copy过程中不会发生扩容。
这两个切片的类型可以不同,但是两个切片的类型的底层类型必须相同
我们可以使用copy函数来在两个数组(取切片)之间或者一个数组(取切片)与一个切片之间复制元素。
package main
import "fmt"
func main() {
type Ta []int
type Tb []int
dest := Ta{1, 2, 3}
src := Tb{5, 6, 7, 8, 9}
n := copy(dest, src)
fmt.Println(n, dest) // 3 [5 6 7]
n = copy(dest[1:], dest) // copy 目标切片是子切片,共享底层切片
fmt.Println(n, dest) // 2 [5 5 6]
a := [4]int{} // 一个数组
n = copy(a[:], src)
fmt.Println(n, a) // 4 [5 6 7 8]
n = copy(a[:], a[2:])
fmt.Println(n, a) // 2 [7 8 7 8]
}注意,做为一个特例,copy函数可以用来将一个字符串中的字节复制到一个字节切片。
语法糖:将字符串当作字节切片使用
内置函数
copy和append可以用来复制和添加切片元素。 事实上,做为一个特例,如果这两个函数的调用中的第一个实参为一个字节切片的话,那么第二个实参可以是一个字符串。(对于append函数调用,字符串实参后必须跟随三个点...。) 换句话说,在此特例中,字符串可以当作字节切片来使用。package main import "fmt" func main() { hello := []byte("Hello ") world := "world!" // helloWorld := append(hello, []byte(world)...) // 正常的语法 helloWorld := append(hello, world...) // 语法糖 fmt.Println(string(helloWorld)) helloWorld2 := make([]byte, len(hello) + len(world)) copy(helloWorld2, hello) // copy(helloWorld2[len(hello):], []byte(world)) // 正常的语法 copy(helloWorld2[len(hello):], world) // 语法糖 fmt.Println(string(helloWorld2)) }
截至目前(Go 1.22),copy函数调用的两个实参均不能为类型不确定的nil。
内置函数 append
我们可以通过调用内置append函数,以一个切片为基础,来添加不定数量的元素并返回一个新的切片。 此新的结果切片包含着基础切片中所有的元素和所有被添加的元素。 注意,基础切片并未被此append函数调用所修改。 当然,如果我们愿意(事实上在实践中常常如此),我们可以将结果切片赋值给基础切片以修改基础切片。
注意,内置append函数是一个变长参数函数(后续介绍)。 它有两个参数,其中第二个参数(形参)为一个变长参数。
s0 := []int{2, 3, 5}
fmt.Println(s0, cap(s0)) // [2 3 5] 3
s1 := append(s0, 7) // 添加一个元素
fmt.Println(s1, cap(s1)) // [2 3 5 7] 6
s2 := append(s1, 11, 13) // 添加两个元素
fmt.Println(s2, cap(s2)) // [2 3 5 7 11 13] 6
s3 := append(s0) // <=> s3 := s0
fmt.Println(s3, cap(s3)) // [2 3 5] 3
s4 := append(s0, s0...) // 以s0为基础添加s0中所有的元素
fmt.Println(s4, cap(s4)) // [2 3 5 2 3 5] 6
s0[0], s1[0] = 99, 789
fmt.Println(s2[0], s3[0], s4[0]) // 789 99 2
对于三个点方式,append函数并不要求第二个实参的类型和第一个实参一致,但是它们的元素类型必须一致。 换句话说,它们的底层类型必须一致。
在上面的程序中,
- 第8行的
append函数调用将为结果切片s1开辟一段新的内存。 原因是切片s0中没有足够的冗余元素槽位来容纳新添加的元素。 第14行的append函数调用也是同样的情况。 - 第10行的
append函数调用不会为结果切片s2开辟新的内存片段。 原因是切片s1中的冗余元素槽位足够容纳新添加的元素。
所以,上面的程序中在退出之前,切片s1和s2共享一些元素,切片s0和s3共享所有的元素。 下面这张图描绘了在上面的程序结束之前各个切片的状态。
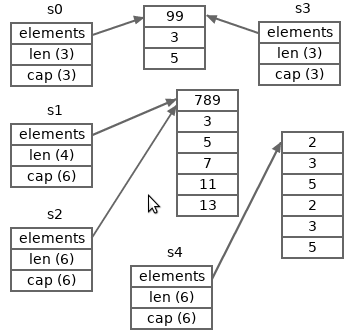
使用append向Slice追加元素时,如果Slice空间不足,将会触发Slice扩容,扩容实际上重新分配一块更大的内存,将原Slice 数据拷贝 进新Slice,然后返回新Slice,扩容后再将数据追加进去。
例如,当向一个capacity为5,且length也为5的Slice再次追加1个元素时,就会发生扩容,如下图所示:
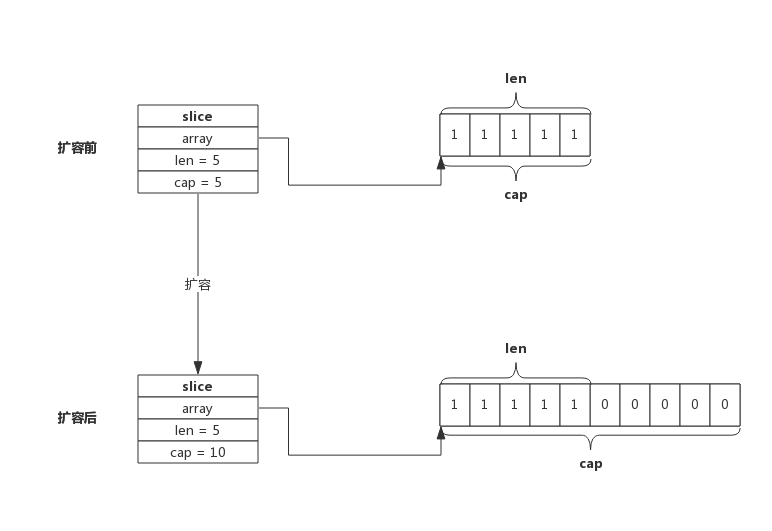
扩容操作只关心容量,会把原Slice数据拷贝到新Slice,追加数据由append在扩容结束后完成。上图可见,扩容后新的Slice长度仍然是5,但容量由5提升到了10,原Slice的数据也都拷贝到了新Slice指向的数组中。
扩容容量的选择遵循以下规则:
- 如果原Slice容量小于1024,则新Slice容量将扩大为原来的2倍;
- 如果原Slice容量大于等于1024,则新Slice容量将扩大为原来的1.25倍;
使用append()向Slice添加一个元素的实现步骤如下:
- 假如Slice容量够用,则将新元素追加进去,Slice.len++,返回原Slice
- 原Slice容量不够,则将Slice先扩容,扩容后得到新Slice
- 将新元素追加进新Slice,Slice.len++,返回新的Slice。
创建切片时可跟据实际需要预分配容量,尽量避免追加过程中扩容操作,有利于提升性能;因为扩容产生的拷贝是一个成本比较大的操作。
截至目前(Go 1.22),append函数调用的第一个实参不能为类型不确定的nil。
当一个切片被用做一个append函数调用中的基础切片,
- 如果添加的元素数量大于此(基础)切片的冗余元素槽位的数量,则一个新的底层内存片段将被开辟出来并用来存放结果切片的元素。 这时,基础切片和结果切片不共享任何底层元素。
- 否则,不会有底层内存片段被开辟出来。这时,基础切片中的所有元素也同时属于结果切片。两个切片的元素都存放于同一个内存片段上。
注意,一般我们不能单独修改一个切片值的某个内部字段,除非使用反射或者非类型安全指针。 换句话说,一般我们只能通过将其它切片赋值给一个切片来同时修改这个切片的三个字段。
切片的应用
切片转化为数组
从 Go 1.20 开始,一个切片可以被转化为一个相同元素类型的数组。 但是如果数组的长度大于被转化切片的长度,则将导致panic产生。 转换过程中将复制所需的元素,因此结果数组和被转化切片不共享底层元素。
数组的长度小于等于被转化的切片长度。
注意是切片的长度,而不是切片的容量。
一个例子:
package main
import "fmt"
func main() {
var s = []int{0, 1, 2, 3}
var a = [3]int(s[1:]) // var a = [3]int(s[0:]) // 也是可以的,对应打印 [0 1 2]
s[2] = 9 // 不共享底层元素
fmt.Println(s) // [0 1 9 3]
fmt.Println(a) // [1 2 3]
_ = [3]int(s[:2]) // panic
}切片转换为数组指针
从Go 1.17开始,一个切片可以被转化为一个相同元素类型的数组的指针类型。 但是如果数组的长度大于被转化切片的长度,则将导致 panic 产生。 转换结果和被转化切片将共享底层元素。
数组的长度小于等于被转化的切片长度。
注意是切片的长度,而不是切片的容量。
package main
type S []int
type A [2]int
type P *A
func main() {
var x []int
var y = make([]int, 0)
var x0 = (*[0]int)(x) // okay, x0 == nil
var y0 = (*[0]int)(y) // okay, y0 != nil
_, _ = x0, y0
var z = make([]int, 3, 5)
var _ = (*[3]int)(z) // okay
var _ = (*[2]int)(z) // okay
var _ = (*A)(z) // okay
var _ = P(z) // okay
var w = S(z)
var _ = (*[3]int)(w) // okay
var _ = (*[2]int)(w) // okay
var _ = (*A)(w) // okay
var _ = P(w) // okay
var _ = (*[4]int)(z) // 会产生panic
var m = make([]int, 5)
var m0 = (*[5]int)(m) // okay
m0[1] = 4
fmt.Println(y) // 0 4 0 0 0
}注意到,仅仅声明的一个切片,转数组指针后是nil,而用make创建的空切片转换成数组指针却不是nil。
单独修改一个切片的长度或者容量
一般来说,一个切片的长度和容量不能被单独修改。一个切片只有通过赋值的方式被整体修改。 但是,事实上,我们可以通过反射的途径来单独修改一个切片的长度或者容量。
package main
import (
"fmt"
"reflect"
)
func main() {
s := make([]int, 2, 6)
fmt.Println(len(s), cap(s)) // 2 6
reflect.ValueOf(&s).Elem().SetLen(3) // 必须是 &s,否则 panic
fmt.Println(len(s), cap(s)) // 3 6
reflect.ValueOf(&s).Elem().SetCap(5)
fmt.Println(len(s), cap(s)) // 3 5
}Q: 必须是对切片的地址进行更改?
A: panic: reflect: call of reflect.Value.Elem on slice Value
// Elem 返回接口 v 包含的值或者指针 v 指向的指针。 // 如果 v 的 Kind 不是 [Interface] 或 [Pointer],它会崩溃。 // 如果 v 为 nil,则返回零值。 func (v Value) Elem() Value
此反射方法的效率很低,远低于一个切片的赋值。
切片克隆
对于当前的Go版本(1.22),最简单的克隆一个切片的方法为:
sClone := append(s[:0:0], s...)通过使用
s[:0:0],你创建了一个从s的起始位置(索引0)开始,长度为0,容量为0的切片。这个切片实际上没有元素和容量。
不共享底层数据,因为是用 append 函数,返回的是一个新的切片。
我们也可以使用下面这种实现。但是和上面这个实现相比,它有一个不完美之处:如果源切片s是一个空切片(但是非nil),则结果切片是一个nil切片。
sClone := append([]T(nil), s...)上面这两种append实现都有一个缺点:它们开辟的内存块常常会比需要的略大一些从而可能造成一点小小的不必要的性能损失。 我们可以使用这两种方法来避免这个缺点:
// 两行make+copy实现:
sClone := make([]T, len(s))
copy(sClone, s)
// 或者下面的make+append实现。
// 对于目前的官方Go工具链1.22版本来说,
// 这种实现比上面的make+copy实现略慢一点。
sClone := append(make([]T, 0, len(s)), s...)上面这两种make方法都有一个缺点:如果s是一个nil切片,则使用此方法将得到一个非nil切片。 不过,在编程实践中,我们常常并不需要追求克隆的完美性。如果我们确实需要,则需要多写几行:
var sClone []T
if s != nil {
sClone = make([]T, len(s))
copy(sClone, s)
}删除一段切片元素
前面已经提到了切片的元素在内存中是连续存储的,相邻元素之间是没有间隙的。所以,当切片的一个元素段被删除时,
- 如果剩余元素的次序必须保持原样,则被删除的元素段后面的每个元素都得前移。
- 如果剩余元素的次序不需要保持原样,则我们可以将尾部的一些元素移到被删除的元素的位置上。
在下面的例子中,假设from(包括)和to(不包括)是两个合法的下标,并且from不大于to。
// 第一种方法(保持剩余元素的次序):
s = append(s[:from], s[to:]...)
// 第二种方法(保持剩余元素的次序):
s = s[:from + copy(s[from:], s[to:])]
// 第三种方法(不保持剩余元素的次序):
if n := to-from; len(s)-to < n {
copy(s[from:to], s[to:])
} else {
copy(s[from:to], s[len(s)-n:])
}
s = s[:len(s)-(to-from)]如果切片的元素可能引用着其它值,则我们应该重置因为删除元素而多出来的元素槽位上的元素值,以避免暂时性的内存泄露:
// "len(s)+to-from"是删除操作之前切片s的长度。
temp := s[len(s):len(s)+to-from]
for i := range temp {
temp[i] = t0 // t0是类型T的零值字面量
}删除一个元素
删除一个元素是删除一个元素段的特例。在实现上可以简化一些。
在下面的例子中,假设i将被删除的元素的下标,并且它是一个合法的下标。对应到上一节中,就是 from = i , to = i+1 。
// 第一种方法(保持剩余元素的次序):
s = append(s[:i], s[i+1:]...)
// 第二种方法(保持剩余元素的次序):
s = s[:i + copy(s[i:], s[i+1:])]
// 上面两种方法都需要复制len(s)-i-1个元素。
// 第三种方法(不保持剩余元素的次序):
s[i] = s[len(s)-1]
s = s[:len(s)-1]如果切片的元素可能引用着其它值,则我们应该重置刚多出来的元素槽位上的元素值,以避免暂时性的内存泄露:
s[len(s):len(s)+1][0] = t0
// 或者
s[:len(s)+1][len(s)] = t0条件性地删除切片元素
// 假设T是一个小尺寸类型。
func DeleteElements(s []T, keep func(T) bool, clear bool) []T {
// result := make([]T, 0, len(s))
result := s[:0] // 无须开辟内存
for _, v := range s {
if keep(v) {
result = append(result, v)
}
}
if clear { // 避免暂时性的内存泄露。
temp := s[len(result):]
for i := range temp {
temp[i] = t0 // t0是类型T的零值
}
}
return result
}注意:如果T是一个大尺寸类型,请慎用T做为参数类型和使用双循环变量for-range代码块遍历元素类型为T的切片。
将一个切片中的所有元素插入到另一个切片中
假设插入位置i是一个合法的下标并且切片elements中的元素将被插入到另一个切片s中。
// 第一种方法:单行实现。
s = append(s[:i], append(elements, s[i:]...)...)
// 上面这种单行实现把s[i:]中的元素复制了两次,并且它可能
// 最多导致两次内存开辟(最少一次)。
// 下面这种繁琐的实现只把s[i:]中的元素复制了一次,并且
// 它最多只会导致一次内存开辟(最少零次)。
// 但是,在当前的官方标准编译器实现中(1.22版本),此
// 繁琐实现中的make调用将会把部分刚开辟出来的元素清零。
// 这其实是没有必要的。所以此繁琐实现并非总是比上面的
// 单行实现效率更高。事实上,它仅在处理小切片时更高效。
if cap(s) >= len(s) + len(elements) {
s = s[:len(s)+len(elements)]
copy(s[i+len(elements):], s[i:])
copy(s[i:], elements)
} else {
x := make([]T, 0, len(elements)+len(s))
x = append(x, s[:i]...)
x = append(x, elements...)
x = append(x, s[i:]...)
s = x
}
// Push(插入到结尾)。
s = append(s, elements...)
// Unshift(插入到开头)。
s = append(elements, s...)特殊的插入和删除:前推/后推,前弹出/后弹出
假设被推入和弹出的元素为e并且切片s拥有至少一个元素。
// 前弹出(pop front,又称shift)
s, e = s[1:], s[0]
// 后弹出(pop back)
s, e = s[:len(s)-1], s[len(s)-1]
// 前推(push front)
s = append([]T{e}, s...)
// 后推(push back)
s = append(s, e)请注意:使用append函数来插入元素常常是比较低效的,因为插入点后的所有元素都要向后挪,并且当空余容量不足时还需要开辟一个更大的内存空间来容纳插入完成后所有的元素。 对于元素个数不多的切片来说,这些可能并不是严重的问题;但是在元素个数很多的切片上进行如上的插入操作常常是耗时的。所以如果元素个数很多,最好使用链表来实现元素插入操作。