基本类型
基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
- 数值类型: 有符号整数 (i8, i16, i32, i64, isize)、 无符号整数 (u8, u16, u32, u64, usize) 、浮点数 (f32, f64)、以及有理数、复数。
- 字符串:字符串字面量和字符串切片 &str。
- 布尔类型: true 和 false。
- 字符类型: 表示单个 Unicode 字符,存储为 4 个字节。
- 单元类型: 即 () ,其唯一的值也是 ()。
类型推导与标注
Rust 是一门静态类型语言,也就是编译器必须在编译期知道所有变量的类型,但这不意味着需要为每个变量指定类型,因为 Rust 编译器可以根据变量的值和上下文中的使用方式来自动推导出变量的类型,但是在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注。
数值类型
不仅仅是数值类型,Rust 也允许在复杂类型上定义运算符,例如在自定义类型上定义 + 运算符,这种行为被称为运算符重载。
整数类型
整数是没有小数部分的数字。
| 长度 | 有符号类型 | 无符号类型 |
|---|---|---|
| 8位 | i8 | u8 |
| 16位 | i16 | u16 |
| 32位 | i32 | u32 |
| 64位 | i64 | u64 |
| 128位 | i128 | u128 |
| 视架构而定 | isize | usize |
当要强调符号时,数字前面可以带上正号或负号。
有符号数字以补码形式存储。
Rust 整型默认使用 i32。
isize 和 usize 类型取决于程序运行的计算机 CPU 类型: 若 CPU 是 32 位的,则这两个类型是 32 位的,同理,若 CPU 是 64 位,那么它们则是 64 位。
isize 和 usize 的主要应用场景是用作集合的索引。
| 数字字面量 | 示例 |
|---|---|
| 十进制 | 98_222 |
| 十六进制 | 0xff |
| 八进制 | 0o77 |
| 二进制 | 0b1111_0000 |
| 字节(仅限 u8) | b’A' |
整型溢出
假设有一个 u8 ,它可以存放从 0 到 255 的值。那么当你将其修改为范围之外的值,比如 256,则会发生整型溢出。 当在 debug 模式编译时,Rust 会检查整型溢出,若存在这些问题,则使程序在编译时 panic 。
在当使用 –release 参数进行 release 模式构建时,Rust 不检测溢出。相反,当检测到整型溢出时,Rust 会按照补码循环溢出(two’s complement wrapping)的规则处理。简而言之,大于该类型最大值的数值会被补码转换成该类型能够支持的对应数字的最小值。 比如在 u8 的情况下,256 变成 0,257 变成 1,依此类推。程序不会 panic,但是该变量的值可能不是你期望的值。
要显式处理可能的溢出,可以使用标准库针对原始数字类型提供的这些方法:
- 使用 wrapping_* 方法在所有模式下都按照补码循环溢出规则处理,例如 wrapping_add。
- 如果使用 checked_* 方法时发生溢出,则返回 None 值。
- 使用 overflowing_* 方法返回该值和一个指示是否存在溢出的布尔值。
- 使用 saturating_* 方法,可以限定计算后的结果不超过目标类型的最大值或低于最小值。
浮点类型
浮点类型数字 是带有小数点的数字,在 Rust 中浮点类型数字也有两种基本类型: f32 和 f64,分别为 32 位和 64 位大小。默认浮点类型是 f64,在现代的 CPU 中它的速度与 f32 几乎相同,但精度更高。
浮点数根据 IEEE-754 标准实现。f32 类型是单精度浮点型,f64 为双精度。
浮点数陷阱
- 浮点数往往是你想要数字的近似表达: 浮点数类型是基于二进制实现的,但是我们想要计算的数字往往是基于十进制,例如 0.1 在二进制上并不存在精确的表达形式,但是在十进制上就存在。这种不匹配性导致一定的歧义性,更多的,虽然浮点数能代表真实的数值,但是由于底层格式问题,它往往受限于定长的浮点数精度,如果你想要表达完全精准的真实数字,只有使用无限精度的浮点数才行。
- 浮点数在某些特性上是反直觉的: 例如大家都会觉得浮点数可以进行比较,对吧?是的,它们确实可以使用 >,>= 等进行比较,但是在某些场景下,这种直觉上的比较特性反而会害了你。因为 f32 , f64 上的比较运算实现的是 std::cmp::PartialEq 特征(类似其他语言的接口),但是并没有实现 std::cmp::Eq 特征,但是后者在其它数值类型上都有定义。
为了避免上面说的两个陷阱,你需要遵守以下准则:
- 避免在浮点数上测试相等性
- 当结果在数学上可能存在未定义时,需要格外的小心
fn main() {
// 断言0.1 + 0.2与0.3相等
assert!(0.1 + 0.2 == 0.3);
}因为二进制精度问题,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。实际上它会 panic。
那如果非要进行比较呢?可以考虑用这种方式 (0.1_f64 + 0.2 - 0.3).abs() < 0.00001 ,具体小于多少,取决于你对精度的需求。
NaN
对于数学上未定义的结果,例如对负数取平方根 -42.1.sqrt() ,会产生一个特殊的结果:Rust 的浮点数类型使用 NaN (not a number)来处理这些情况。
所有跟 NaN 交互的操作,都会返回一个 NaN,而且 NaN 不能用来比较。
出于防御性编程的考虑,可以使用 is_nan() 等方法,可以用来判断一个数值是否是 NaN :
fn main() {
let x = (-42.0_f32).sqrt();
if x.is_nan() {
println!("未定义的数学行为")
}
}数字运算
fn main() {
// 加法
let sum = 5 + 10;
// 减法
let difference = 95.5 - 4.3;
// 乘法
let product = 4 * 30;
// 除法
let quotient = 56.7 / 32.2;
// 求余(取模)
let remainder = 43 % 5;
}位运算
| 运算符 | 说明 |
|---|---|
| & 位与 | 相同位置均为1时则为1,否则为0 |
| | 位或 | 相同位置只要有1时则为1,否则为0 |
| ^ 异或 | 相同位置不相同则为1,相同则为0 |
| ! 位非 | 把位中的0和1相互取反,即0置为1,1置为0 |
| « 左移 | 所有位向左移动指定位数,右位补0 |
| » 右移 | 所有位向右移动指定位数,带符号移动(正数补0,负数补1) |
序列(range)
Rust 提供了一个非常简洁的方式,用来生成连续的数值,例如 1..5,生成从 1 到 4 的连续数字,不包含 5 ;1..=5,生成从 1 到 5 的连续数字,包含 5,它的用途很简单,常常用于循环中:
for i in 1..=5 {
println!("{}",i);
}序列只允许用于数字或字符类型,原因是:它们可以连续,同时编译器在编译期可以检查该序列是否为空,字符和数字值是 Rust 中仅有的可以用于判断是否为空的类型。
for i in 'a'..='z' {
println!("{}",i);
}使用 As 完成类型转换
Rust 中可以使用 As 来完成一个类型到另一个类型的转换,其最常用于将原始类型转换为其他原始类型,但是它也可以完成诸如将指针转换为地址、地址转换为指针以及将指针转换为其他指针等功能。
类型转换必须是显式的。
有理数和复数
有理数和复数并未包含在标准库中:
- 有理数和复数
- 任意大小的整数和任意精度的浮点数
- 固定精度的十进制小数,常用于货币相关的场景
好在社区已经开发出高质量的 Rust 数值库:num。
字符、布尔、单元类型
字符类型(char)
你可以把它理解为英文中的字母,中文中的汉字。
fn main() {
let c = 'z';
let z = 'ℤ';
let g = '国';
let heart_eyed_cat = '😻';
}所有的 Unicode 值都可以作为 Rust 字符,包括单个的中文、日文、韩文、emoji 表情符号等等,都是合法的字符类型。
由于 Unicode 都是 4 个字节编码,因此字符类型也是占用 4 个字节:
Rust 的字符只能用 '' 来表示, "" 是留给字符串的。
布尔(bool)
Rust 中的布尔类型有两个可能的值:true 和 false,布尔值占用内存的大小为 1 个字节。
单元类型
单元类型就是 () ,唯一的值也是 () 。
fn main() 函数就返回这个单元类型 ()。你不能说 main 函数无返回值,因为没有返回值的函数在 Rust 中是有单独的定义的:发散函数( diverge function ),顾名思义,无法收敛的函数。
例如常见的 println!() 的返回值也是单元类型 ()。
你可以用 () 作为 map 的值,表示我们不关注具体的值,只关注 key。 这种用法和 Go 语言的 struct{} 类似,可以作为一个值用来占位,但是完全不占用任何内存。
语句与表达式
Rust 的函数体是由一系列语句组成,最后由一个表达式来返回值。
fn add_with_extra(x: i32, y: i32) -> i32 {
let x = x + 1; // 语句
let y = y + 5; // 语句
x + y // 表达式
}语句会执行一些操作但是不会返回一个值,而表达式会在求值后返回一个值。
这种基于语句(statement)和表达式(expression)的方式是非常重要的,基于表达式是函数式语言的重要特征,表达式总要返回值。
语句
let a = 8;
let b: Vec<f64> = Vec::new();
let (a, c) = ("hi", false);以上都是语句,它们完成了一个具体的操作,但是并没有返回值,因此是语句。
由于 let 是语句,因此不能将 let 语句赋值给其它值,如下形式是错误的:
let b = (let a = 8);表达式
表达式会进行求值,然后返回一个值。例如 5 + 6,在求值后,返回值 11,因此它就是一条表达式。
表达式可以成为语句的一部分,例如 let y = 6 中,6 就是一个表达式,它在求值后返回一个值 6(有些反直觉,但是确实是表达式)。
调用一个函数是表达式,因为会返回一个值,调用宏也是表达式,用花括号包裹最终返回一个值的语句块也是表达式,总之,能返回值,它就是表达式。
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {}", y);
}表达式不能包含分号,一旦你在表达式后加上分号,它就会变成一条语句,再也不会返回一个值。
表达式如果不返回任何值,会隐式地返回一个 () 。
函数
fn add(i: i32, j: i32) -> i32 {
i + j
}声明函数的关键字 fn ,函数名 add(),参数 i 和 j,参数类型和返回值类型都是 i32
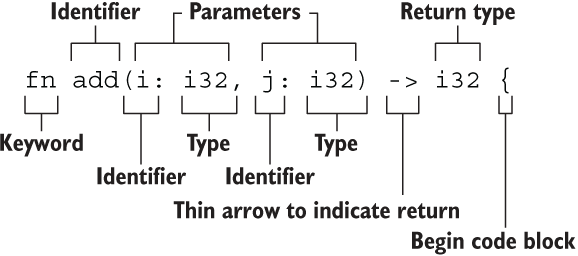
函数要点
- 函数名和变量名使用蛇形命名法(snake case),例如
fn add_two() -> {}。 - 函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可。
- 每个函数参数都需要标注类型。
对于 type-level 的构造 Rust 倾向于使用驼峰命名法,而对于 value-level 的构造使用蛇形命名法。
函数返回
函数的返回值就是函数体最后一条表达式的返回值,当然我们也可以使用 return 提前返回。
fn plus_five(x:i32) -> i32 {
x + 5
}
fn main() {
let x = plus_five(5);
println!("The value of x is: {}", x);
}fn plus_or_minus(x:i32) -> i32 {
if x > 5 {
return x - 5
}
x + 5
}
fn main() {
let x = plus_or_minus(5);
println!("The value of x is: {}", x);
}无返回值
单元类型 (),是一个零长度的元组。它可以用来表达一个函数没有返回值。
- 函数没有返回值,那么返回一个
() - 通过
;结尾的语句返回一个()
例如下面的 report 函数会隐式返回一个 ():
use std::fmt::Debug;
fn report<T: Debug>(item: T) {
println!("{:?}", item);
}上面的函数返回值相同,但是下面的函数显式的返回了 ():
fn clear(text: &mut String) -> () {
*text = String::from("");
}永不返回的发散函数 !
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverge function ),特别的,这种语法往往用做会导致程序崩溃的函数:
fn forever() -> ! {
loop {
//...
};
}上面的函数创建了一个无限循环,该循环永不跳出,因此函数也永不返回。